

Introduction
Retrieval Augmented Generation, also known as RAG, is a technique in Natural Language Processing that combines the strengths of retrieval-based methods and generative models as an approach for generating high-quality, contextually relevant responses to queries. It operates by first retrieving relevant documents or information from a pre-existing knowledge base, typically a vector database, and then using this retrieved data to generate coherent and contextually appropriate text, typically through the use of a Large Language Model (LLM). This dual approach allows RAG systems to provide more detailed and context-aware answers compared to traditional generative models that rely solely on their internal knowledge.
Key processes in RAG
RAG involves several critical processes to ensure the efficient extraction, processing, and utilization of data. These processes include data extraction, data wrangling, chunking, embedding model application, setting up retrieval, query encoding, and LLM (Large Language Model) generation. Each step plays a vital role in creating a robust RAG system that can provide accurate and contextually relevant information. Each of these processes can be connected through the use of data pipelines.
We can identify three key data pipelines within a RAG system: indexing pipeline which is in charge of transforming raw data into vectors and populating a vector database; retriever pipeline, which is responsible for applying the same embedding model on the question, and obtaining the relevant information from the database through a retriever algorithm, and a generator pipeline that combines the retrieved answer with an LLM, enabling grounded text generation.
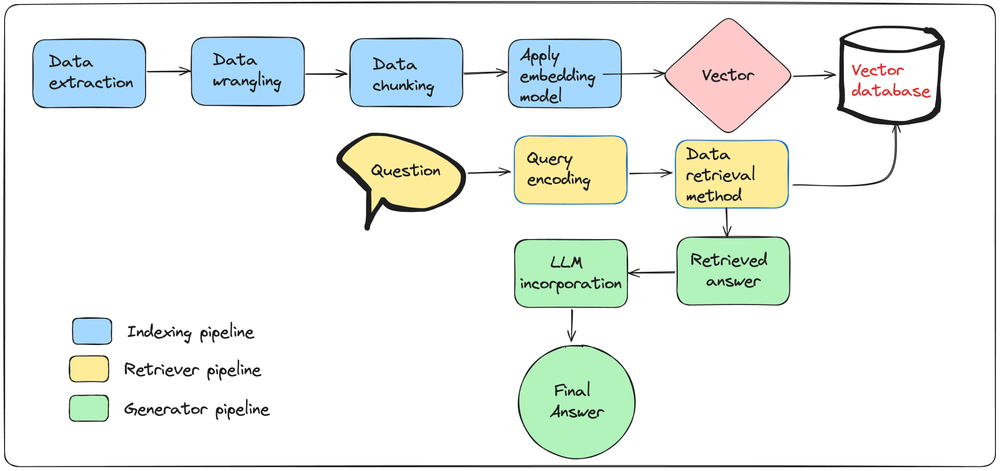
Let's expand on each of these processes.
Data Extraction
Data extraction is the first step in the RAG pipeline. This process involves collecting raw data from various sources, such as databases, APIs, web scraping, or document repositories. The goal is to gather all relevant information that the RAG system will use to generate responses.
Key Activities:
- Identifying and accessing data sources.
- Collecting structured and unstructured data.
- Ensuring data is up-to-date and comprehensive.
Data Wrangling
Once the raw data is extracted, it needs to be cleaned and formatted for further processing. Data wrangling involves transforming the raw data into a structured format that can be easily handled by the RAG system.
Key Activities:
- Cleaning data by removing duplicates, correcting errors, and handling missing values.
- Structuring data into a consistent format (e.g., JSON, CSV).
- Normalizing and standardizing data to ensure uniformity.
Data Chunking
After the data is cleaned and structured, it is divided into smaller, manageable pieces or chunks. Chunking helps in handling large datasets efficiently and ensures that the retrieval process can target specific pieces of information.
Key Activities:
- Splitting data into coherent chunks based on logical segments (e.g., paragraphs, sections).
- Ensuring chunks are of optimal size for processing and retrieval.
- Tagging or labeling chunks for easy identification.
Applying an Embedding Model
Embedding models convert text data into numerical vectors that capture the semantic meaning of the text. These vectors are then used to populate a vector database, enabling efficient retrieval based on semantic similarity.
Key Activities:
- Selecting an appropriate embedding model.
- Converting text chunks into vector representations.
- Storing vectors in a vector database for fast and accurate retrieval.
Setting Up Retrieval
Retrieval involves setting up a mechanism to search and fetch relevant chunks of information from the vector database based on the input query. This process is critical for ensuring that the most pertinent data is available for generating responses.
Key Activities:
- Implementing a retrieval algorithm that can search the vector database efficiently.
- Optimizing retrieval performance to handle real-time queries.
- Ensuring high accuracy in matching queries with relevant data chunks.
Query Encoding
Query encoding is the process of converting the user's query into a vector that can be used to search the vector database. This step ensures that the retrieval system can understand and process the input query effectively.
Key Activities:
- Using the same embedding model to encode queries as was used for data chunks.
- Ensuring the query vector accurately captures the intent and context of the query.
- Handling different query formats and variations.
LLM Generation
The final step involves using a Large Language Model (LLM) to generate responses based on the retrieved data chunks. The LLM synthesizes the information and produces coherent and contextually relevant text.
Key Activities:
- Integrating the LLM with the retrieval system.
- Feeding the retrieved data chunks to the LLM.
- Generating and refining responses to ensure accuracy and relevance.
In summary, the key processes in RAG—data extraction, wrangling, chunking, embedding model application, retrieval setup, query encoding, and LLM generation—work together to create a collection of pipelines. These pipelines enable the RAG system to provide high-quality, contextually relevant responses by leveraging the latest and most pertinent data available.
Importance of real-time implementation in RAG
Incorporating real-time data processing techniques within RAG is pivotal. By accessing and using up-to-date information, RAG systems can deliver responses that reflect the most current data, trends, and events. This capability is especially valuable in scenarios that demand dynamic and timely information. Let's compare real-time processing vs batch processing.
Real-time vs. batch processing
One of the core strengths of real-time RAG is its ability to update the database continuously, as opposed to performing updates in batches. Below we outline the advantages and drawbacks of updating data in real time:
| Real-time data updates | |
|---|---|
| Advantages | |
| Enhanced Accuracy | Real-time updates ensure that the model always has access to the most accurate and current information, reducing the risk of generating outdated or incorrect responses. |
| Instantaneous Data Availability | With real-time updates, new information is immediately available to the RAG system. This is particularly beneficial in fast-paced environments where the latest data can significantly impact the quality of the generated responses. |
| Improved User Experience | Users receive the most relevant and up-to-date answers, enhancing their overall experience and satisfaction. |
| Drawbacks | |
| Resource Intensity | Maintaining real-time updates can be resource-intensive, requiring continuous monitoring and integration of new data, which can increase operational costs. |
| Complexity in Implementation | Implementing real-time updates can be technically complex, requiring sophisticated infrastructure and data management practices. |
| Potential for Overload | Continuous data influx can overwhelm the system, leading to potential downtimes or slower response times if not managed properly. |
Let's now take a look at the advantages and drawbacks of updating data using batch methods.
| Batch updates | |
|---|---|
| Advantages | |
| Efficient Resource Use | Batch updates can be scheduled during off-peak hours, making better use of system resources and reducing the impact on performance during high-demand periods. |
| Simplified Implementation | Implementing batch updates can be simpler and less complex, as it involves periodic data integration rather than continuous monitoring. |
| Cost-Effective | Batch processing can be more cost-effective by reducing the need for constant resource allocation and allowing for more planned and controlled data handling. |
| Drawbacks | |
| Delayed Information | Batch updates occur at scheduled intervals, leading to a lag between the data generation and its availability to the RAG system. This can result in the model using outdated information. |
| Stale Data | During the intervals between updates, the data can become outdated, leading to less relevant and potentially inaccurate responses. |
| Bulk Processing Challenges | Handling large volumes of data in a single update can create processing bottlenecks and require substantial computational resources. |
Best of both worlds: micro batching
Micro batching is an approach that combines the strengths of both real-time and batch processing methods. It involves updating data at more frequent, smaller intervals than traditional batch processing. This hybrid method aims to reduce the lag between data generation and its availability to systems while maintaining resource efficiency and minimizing the complexity associated with continuous real-time updates.
Implementing micro batching typically involves setting up a system that can handle smaller, more frequent updates efficiently. This can include:
Interval Scheduling:
- Defining appropriate intervals for updates that balance the need for current information with resource availability. These intervals are shorter than traditional batch processing but longer than continuous real-time updates.
Efficient Data Handling:
- Optimizing data processing pipelines to handle smaller batches quickly and effectively. This can involve using advanced data processing frameworks and ensuring the infrastructure can support frequent updates.
Monitoring and Adaptation:
- Continuously monitoring system performance and data influx to adjust the micro batching intervals as needed. This ensures the system remains responsive and efficient under varying conditions.
In summary, micro batching offers a balanced approach to data updates, combining the advantages of both real-time and batch processing methods. It ensures timely data availability, efficient resource use, improved accuracy, and scalability, making it a suitable solution for systems requiring up-to-date information without the high resource demands of continuous real-time updates.
Real-time database updates and LLM fine-tuning
In the context of LLM applications, fine-tuning and real-time updates serve different purposes but can be complementary. Let's take a look at the key characteristics of each.
Fine-tuning an LLM
- Model Adaptation: Fine-tuning involves adjusting the model's parameters based on a specific dataset to improve its performance on particular tasks. This process can make the model more proficient at understanding and generating domain-specific content.
- Resource-Consuming: Fine-tuning is a more time-consuming process as it requires training the model on the new data, which requires curating a dataset, and can entail using considerable computational resources, depending on the model size and data volume, as well as the success of the model after training.
- Periodic Re-training: Fine-tuning is not typically performed in real-time but rather periodically, to incorporate new information and improve the model's performance over time.
Real-time updates of a database in a RAG system
- Immediate integration: Real-time updates focus on integrating new information into the database that the LLM retrieves from, without changing the model's underlying parameters.
- Continuous refresh: The information the model accesses is continuously refreshed, ensuring responses are based on the latest available data.
While fine-tuning enhances the model's ability to understand and generate text based on specific datasets, real-time updates ensure the model has access to the most current information. Together, they ensure both high performance and up-to-date responses. We will now turn our attention to a sample implementation of a real time workflow within RAG leveraging the Python ecosystem.
Building real-time RAG with Python with Bytewax
In this section, we will learn how we can leverage Bytewax along with the Python ecosystem to build scalable and production-ready RAG systems.
Introduction to Bytewax
Bytewax is a Python-native distributed stream processing engine designed to handle real-time data processing with a focus on scalability and performance. Bytewax stands out for its combination of a Python interface and a robust Rust core and application of timely dataflow, providing both ease of use and high efficiency. It is suitable for deployment in various environments, including cloud, on-premises, and edge devices, making it a versatile solution for a wide range of real-time data processing needs.
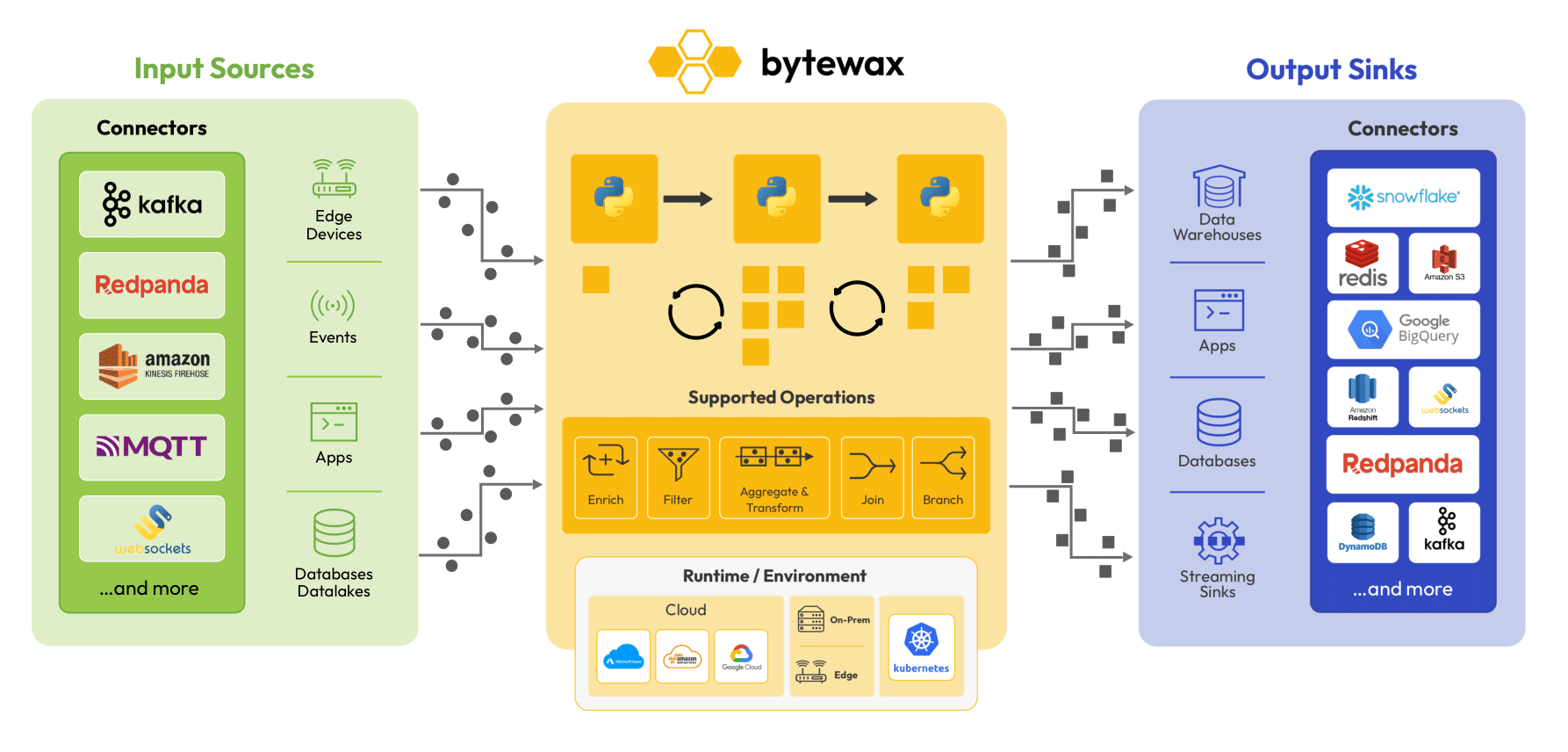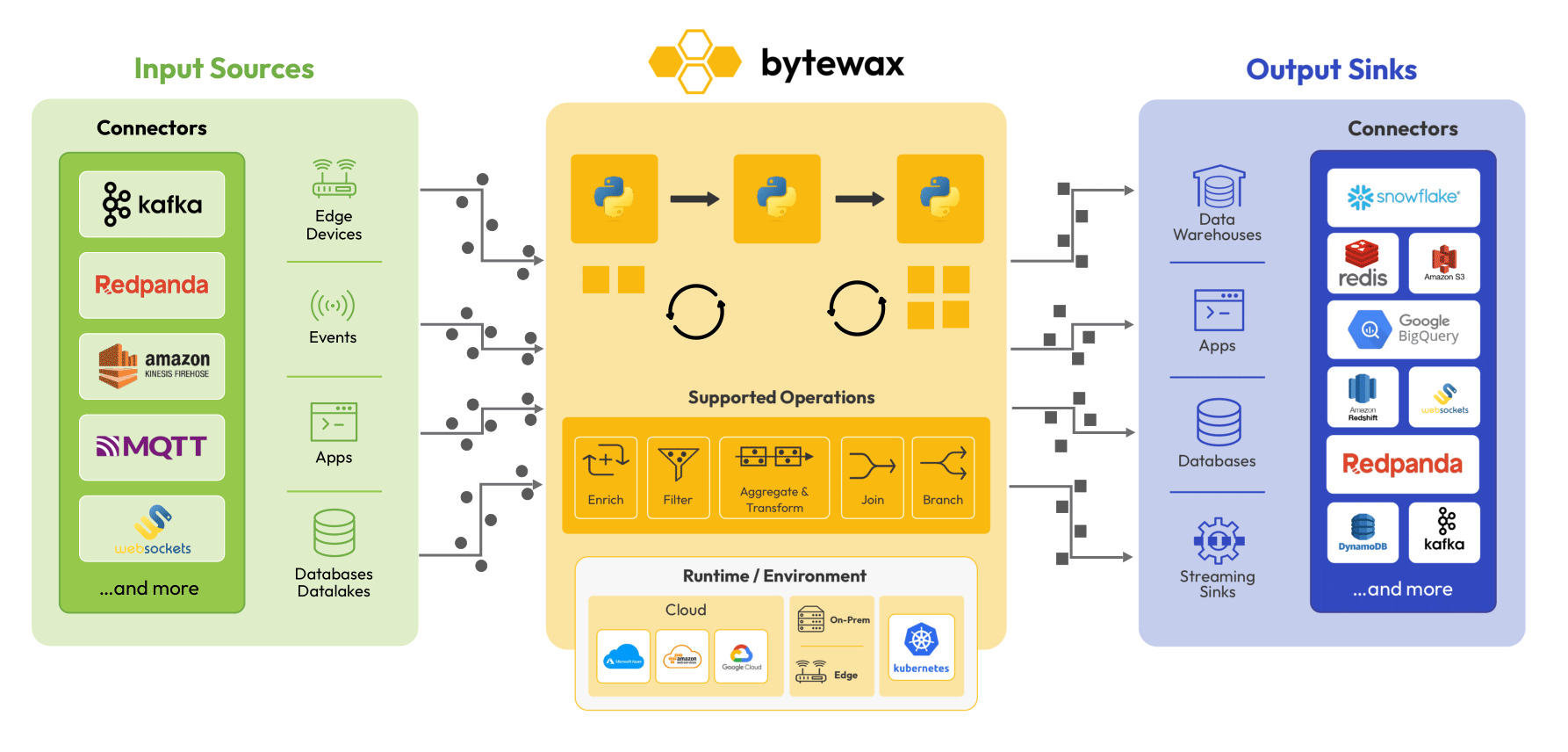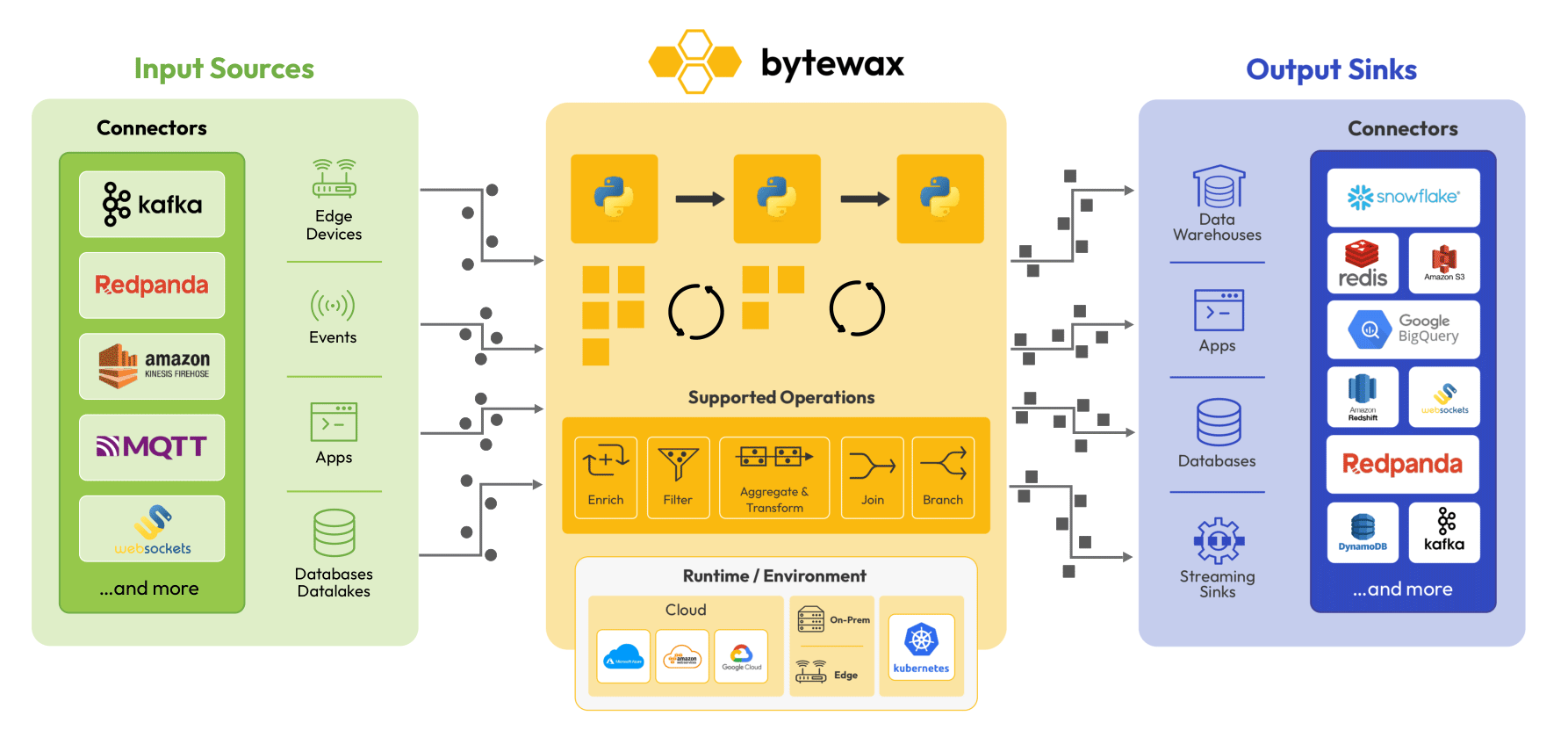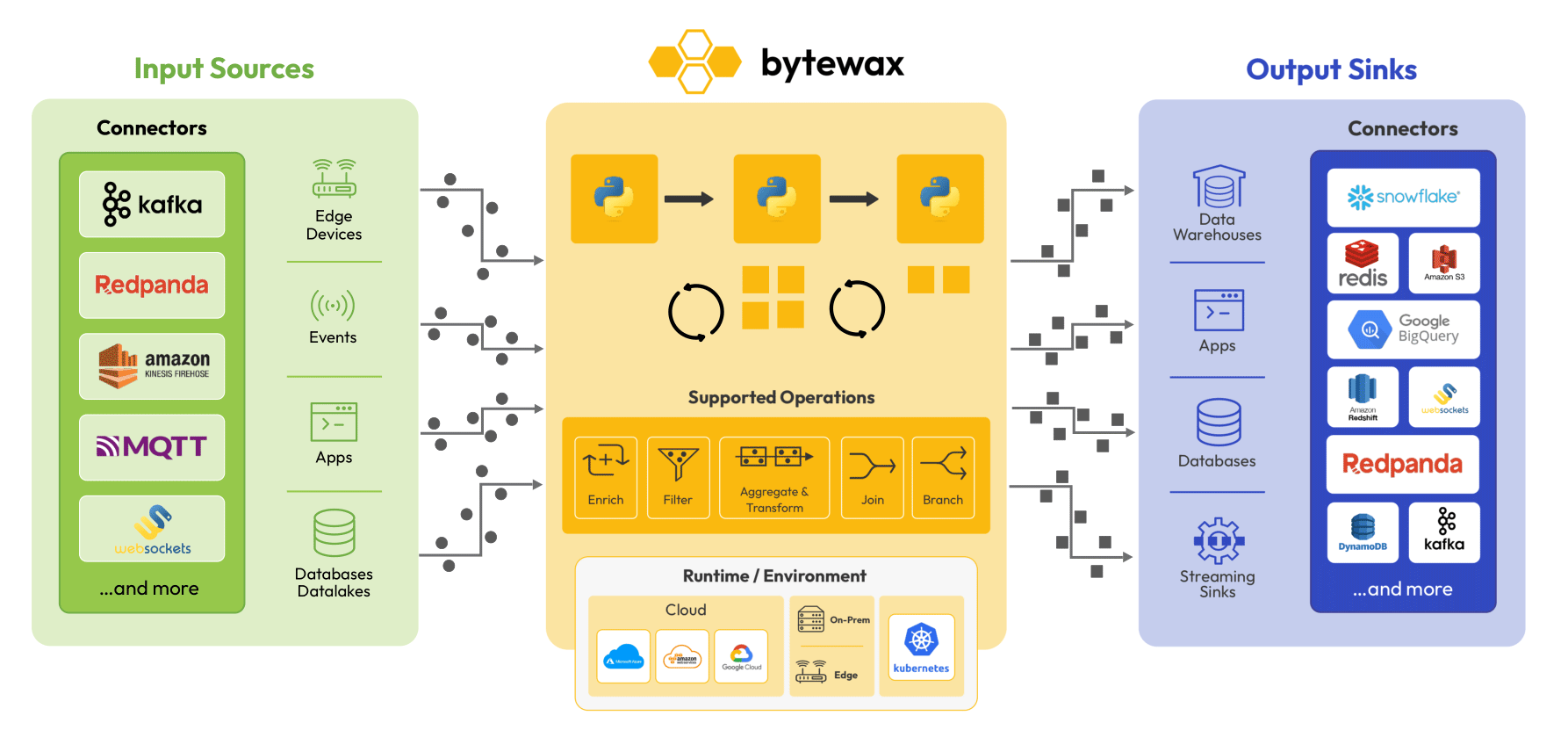
Key Features:
- Python Skin, Rust Heart: Bytewax offers a Python interface for ease of use while using Rust for performance-intensive operations.
- Scalability: Designed to scale horizontally across multiple nodes, Bytewax can handle increasing data volumes effortlessly.
- Performance: The Rust-based core ensures high-performance data processing, making it suitable for time-sensitive applications.
- Statefulness: Bytewax supports stateful processing, allowing it to maintain and manage state information across data streams effectively.
Additionally, it provides several data processing capabilities:
- Enrich: Enhance incoming data streams with additional information from other sources or computations.
- Branch: Split data streams into multiple paths for parallel processing or different processing logic.
- Filter: Remove unwanted data points from the stream based on specific criteria.
- Aggregate: Perform real-time aggregations on data streams, such as calculating sums, averages, or counts.
- Transform: Modify data within the stream to fit the desired format or structure.
- Join: Combine data from different streams or sources, enabling complex data relationships and correlations.
Through Bytewax we can incorporate real-time processing capabilities while enjoying the diversity of the Python ecosystem.
The LLM Python ecosystem meets real time processing with Bytewax
With the introduction of LLM applications, a wide variety of Python packages were introduced to easily incorporate LLMs into existing data science workflows.
In this blog, we shared how we can combine an LLM orchestrator such as Haystack by deepset to set up pipelines for each of the key processes in RAG systems, and apply them in a Bytewax dataflow as map operations. Let's explore a more advanced architecture involving production-ready LLMs and embedding models.
In the architecture below, we are focusing on processing unstructured information coming from the EDGAR advanced search containing information on public fillings as well as news coming from Benzinga News.
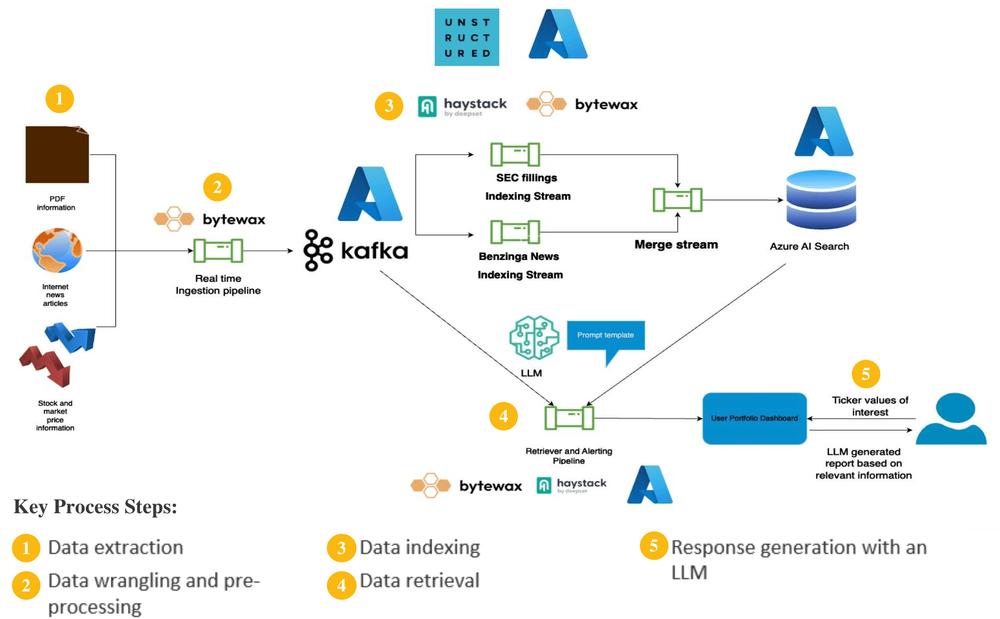
In the webinar below we outlined in detail how we implemented the solution:
Workshop: Building Real-Time RAG for Financial Data & News with Bytewax, Microsoft & Unstructured
A Bytewax dataflow is implemented to generate JSONL files with URL and metadata and populate a Kafka instance. A complete code implementation that performs this can be found here.
We can then initialize a second set of Bytewax dataflows that connect to the Kafka instance, and extract, clean, chunk and embed the content of the sites through an indexing pipeline. For this specific application, embedding models hosted on Azure AI were used, with Azure AI Search implemented as the vector database.
Real-time indexing pipeline strategy
- Initialize Bytewax dataflow and input
- Build Haystack custom components for the Unstructured and Azure embedding functionality
- Connect components into a Haystack pipeline
- Define pipeline as custom component so it can take Bytewax event as input
- Plug pipeline into Bytewax dataflow as a map operator
- Output stream into a Bytewax custom connector
Below we can see a mermaid graph for the indexing pipelines containing custom components to extract, process and embed the content of EDGAR and Benzinga sites:
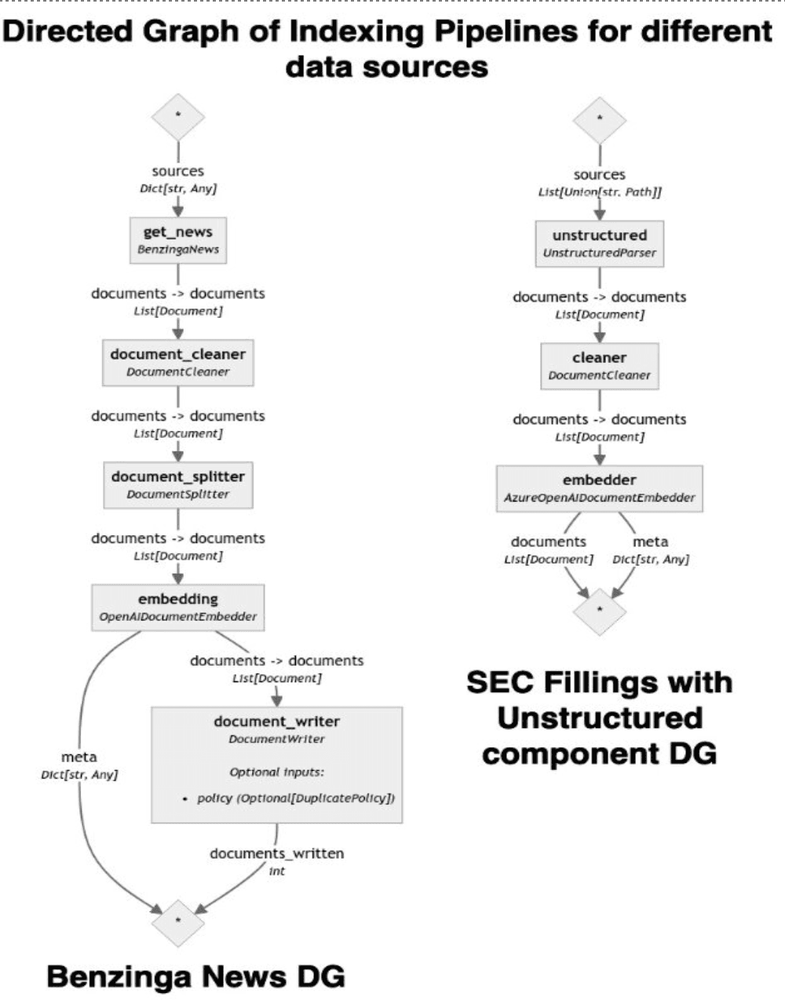
The complete code implementation for the indexing pipelines and their incorporation into a Bytewax dataflow can be found here.
Future work
Once the real time indexing pipeline has been set up, separate pipelines and dataflows can be used to retrieve and generate appropriate responses. One application we're eager to develop is a report generator through a Streamlit application taking as input tickers and a question in natural language, that returns an LLM-generated report that uses the database updated in real time.
Conclusion
In this blog we outlined the key processes in RAG and how these processes can be put together through the use of key pipelines: indexing pipeline, retriever pipeline and generator pipeline. We discussed the importance of real-time processing, discussed the pros and cons of real-time vs batch-based processing, and motivated micro-batching as a solution that leverages the strengths of both approaches.
We introduced Bytewax - a Python-native stream processing engine that leverages the speed of Rust with the diversity in the Python ecosystem, and showcased an example involving real-time processing of financial news and public filling information.
By leveraging the open source ecosystem along with Bytewax, we can develop complex yet scalable RAG systems that enable us to ground an LLM's response with up-to-date data. In future blogs, we will expand in more detail the code-based implementation that we followed in this example.
Stay updated with our newsletter
Subscribe and never miss another blog post, announcement, or community event.
Real-time Data Platform with Redpanda, Bytewax, Arrow and Clickhouse
Laura Funderburk
Senior Developer AdvocateLaura Funderburk holds a B.Sc. in Mathematics from Simon Fraser University and has extensive work experience as a data scientist. She is passionate about leveraging open source for MLOps and DataOps and is dedicated to outreach and education.

