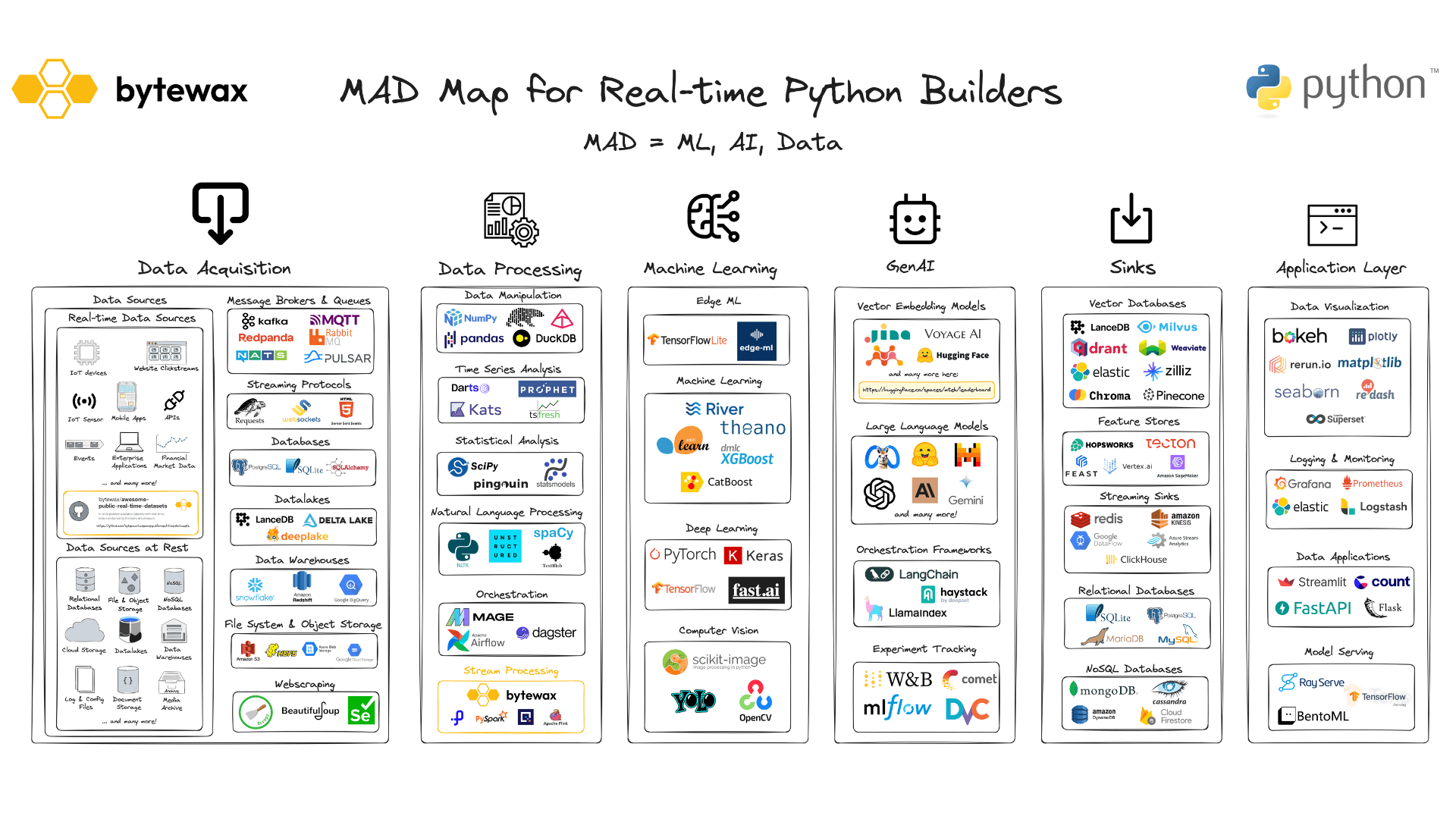

Why we built the Bytewax MAD Map
One of Bytewax's biggest draws is its seamless integration with the Python ecosystem. However, we struggled to find a comprehensive overview of libraries and tools relevant to real-time Python developers. While there are excellent overviews of the data landscape, such as Matt Turck's MAD Landscape and Yujian Tang's monthly updated LLM App Stack, these resources don't specifically address the needs of Python developers working with real-time data. This gap led us down the rabbit hole to create our own MAD (Machine Learning, AI, Data) Map.
Originally, the Bytewax MAD Map began as a single presentation slide listing about 20 Python libraries. After sharing this initial list on LinkedIn, the response from the community was overwhelmingly positive, leading to the expansion of the list with more tools. Thanks to continuous community feedback, further research, and the efforts of the Bytewax team, the MAD map has now grown to include over 100 tools.
Introduction
The idea of the Bytewax MAD Map for Real-time Python Builders is to give an overview of Python libraries and other tools that can be used alongside Bytewax for real-time IoT, Machine Learning, and GenAI use cases. Rather than attempting to cover every tool available, we focused on the libraries and tools our developers most frequently use. You might notice a preference for open-source tools; this is intentional and reflects the values of our developer community.
Data Acquisition
Data Sources
Data sources are the origin points from which data is collected. They can be divided into real-time sources, which provide immediate data streams, and at-rest sources, which store historical data. Both types of sources can be combined for building comprehensive real-time applications.
Real-time Data Sources
Real-time data sources provide immediate data streams, which are crucial for applications requiring up-to-the-second information.
Examples for real-time data sources are:
- IoT Devices
- IoT Sensors
- Website Clickstreams
- Mobile Apps
- APIs
- Events
- Enterprise Applications
- Financial Market Data ... and of course there is many more!
At Bytwax we maintain a list of awesome public real-time datasets and sources, which can be found here: GitHub Repo
Data Sources at Rest
Data sources at rest include various storage solutions that hold data which can be queried and processed as needed. These sources can store historical data, which is essential for comprehensive analytics and often provides the necessary context for streaming data.
Examples for data sources at rest:
- Relational Databases
- Files & Object Storage
- NoSQL Databases
- Cloud Storage
- Datalakes
- Data Warehouses
- Document Storage
- Media Archives
- Log & Config Files
Message Brokers & Queues
Message brokers and queues are systems that facilitate the reliable transfer of data between applications, ensuring consistent and orderly data delivery.
- Kafka - A distributed message broker that uses a publish-subscribe model, designed for high-throughput and fault-tolerant data delivery. → GitHub Repo
- Redpanda - A Kafka-compatible message broker optimized for performance, offering low-latency message delivery and high reliability. → GitHub Repo
- RabbitMQ - An open-source message broker that supports various messaging protocols and provides robust queuing capabilities. → GitHub Repo
- MQTT - A lightweight messaging protocol optimized for low-bandwidth and high-latency networks, commonly used for IoT devices. → GitHub Repo
- Pulsar - A multi-tenant, high-performance message broker and pub-sub system, designed for scalability and low latency. → GitHub Repo
- NATS - A lightweight, high-performance messaging system offering simple publish-subscribe and request-reply patterns, ideal for cloud-native applications and IoT. → GitHub Repo
Streaming Protocols
Streaming protocols are frameworks that enable continuous data streams with low latency, allowing for real-time data transfer.
- Websockets - A communication protocol that provides full-duplex communication channels over a single TCP connection, enabling real-time data exchange between clients and servers. → GitHub Repo
- Requests - While typically used for HTTP requests, the Requests library can be utilized for long-polling techniques, enabling the server to push data to the client when available. → GitHub Repo
- Server-Sent Events - A server push technology that allows servers to send real-time updates to the client over a single HTTP connection, ideal for live notifications and updates.
Databases
Databases are foundational systems for storing and querying data efficiently, supporting structured data storage and complex queries.
- PostgreSQL - An advanced open-source relational database known for its robustness, extensibility, and support for complex queries and transactions. → GitHub Repo
- SQLite - A self-contained, serverless SQL database engine that is lightweight and highly reliable, commonly used in embedded systems and mobile applications. → GitHub Repo
- MySQL - An open-source relational database management system known for its ease of use, performance, and scalability, widely used in web applications. → GitHub Repo
- SQL Server - A relational database management system developed by Microsoft, offering a wide range of enterprise-level features and integrations. → GitHub Repo
- ClickHouse - A fast open-source columnar database management system optimized for online analytical processing (OLAP) and real-time analytics. → GitHub Repo
Datalakes
Datalakes provide scalable storage for large datasets, allowing raw data to be stored in its native format and processed as needed.
- LanceDB - A datalake optimized for large-scale data storage and retrieval, designed to handle a wide variety of data types and formats, allowing raw data to be stored and processed efficiently. → GitHub Repo
- Delta Lake - An open-source storage layer that brings ACID transactions to big data workloads, enabling reliable and scalable datalake solutions for managing and processing raw data. → GitHub Repo
- Deeplake - A datalake specifically designed for deep learning applications, facilitating efficient storage, management, and access to large-scale datasets used in machine learning workflows. → GitHub Repo
Data Warehouses
Data warehouses offer optimized storage for structured data and support complex queries, providing powerful analytics capabilities.
- Snowflake - Cloud-native data warehouse known for its separation of storage and compute, enabling elastic scaling and advanced data sharing capabilities. → GitHub Repo
- BigQuery - Serverless, highly scalable data warehouse that supports ANSI SQL, offering powerful analytics with built-in machine learning and real-time data processing. → GitHub Repo
- Amazon Redshift - Fully managed, large-scale data warehouse that integrates deeply with the AWS ecosystem, optimized for fast query performance using columnar storage and parallel query execution. → GitHub Repo
File System & Object Storage
File systems and object storage solutions store unstructured data and provide versatile storage and retrieval capabilities.
- Hadoop HDFS - A distributed file system designed to run on commodity hardware, providing high throughput access to large datasets and fault-tolerant storage. → GitHub Repo
- Amazon S3 - An object storage service offering scalable, high-availability storage with comprehensive security and compliance capabilities.
- Azure Blob Storage - A Microsoft cloud-based object storage solution optimized for storing massive amounts of unstructured data, with seamless integration into the Azure ecosystem.
- Google Cloud Storage (GCS) - A scalable and durable object storage service with high availability, designed for storing any amount of data and retrieving it as needed. → GitHub Repo
Webscraping
Webscraping tools enable data extraction from web sources, gathering information from websites for processing and analysis.
- Scrapy - Open-source and collaborative web crawling framework for Python, designed to extract data from websites and process them as needed efficiently. → GitHub Repo
- BeautifulSoup - Python library for parsing HTML and XML documents, providing idiomatic ways of navigating, searching, and modifying parse trees. → GitHub Repo
- Selenium - Suite of tools for automating web browsers, enabling the extraction of data from web pages that require user interaction or JavaScript execution for rendering. → GitHub Repo
Data Processing
Data Manipulation
Data manipulation libraries provide tools for cleaning, transforming, and validating data, ensuring it is in the correct format and structure for analysis.
- NumPy - Fundamental library for numerical computing in Python, providing support for large, multi-dimensional arrays and a collection of mathematical functions to operate on these arrays. → GitHub Repo
- pandas - Powerful data manipulation and analysis library, offering data structures like DataFrame for handling structured data efficiently and tools for various data operations. → GitHub Repo
- Polars - Lightning-fast DataFrame library implemented in Rust and designed for performance, supporting out-of-core data processing and lazy evaluation for large datasets. → GitHub Repo
- DuckDB - In-process SQL OLAP database management system that offers efficient data manipulation and querying capabilities, designed for analytical workflows. → GitHub Repo
- Pydantic - Data validation and settings management library that uses Python type annotations to validate and parse data, ensuring data integrity and correctness in applications. → GitHub Repo
Time Series Analysis
Time series analysis tools are used for forecasting and analyzing trends in time-dependent data, providing insights into patterns and future trends.
- Darts - Library for easy manipulation and forecasting of time series, supporting a variety of models and methods for prediction. → GitHub Repo
- Prophet - Open-source tool developed by Meta for forecasting time series data, designed to handle seasonality and holidays with ease. → GitHub Repo
- Kats - Comprehensive toolkit from Meta for analyzing time series data, providing models, diagnostics, and transformations for accurate forecasting. → GitHub Repo
- tsfresh - Library for automated extraction of relevant features from time series data, useful for classification and regression tasks. → GitHub Repo
Statistical Analysis
Statistical analysis tools offer advanced statistical functions for complex data analysis, supporting a wide range of statistical tests and models.
- SciPy - A library used for scientific and technical computing, providing modules for optimization, integration, interpolation, eigenvalue problems, algebraic equations, and other advanced mathematical functions. → GitHub Repo
- Pingouin - A statistical package that provides a comprehensive set of easy-to-use statistical tools, including t-tests, ANOVA, correlation, regression, and more. → GitHub Repo
- statsmodels - A module that allows users to explore data, estimate statistical models, and perform statistical tests, including linear and nonlinear regression, time series analysis, and hypothesis testing. → GitHub Repo
Natural Language Processing
Natural Language Processing (NLP) libraries facilitate text analysis and processing, enabling applications to understand and interpret language data.
- spaCy - A library designed for efficient NLP, offering pre-trained models and tools for tasks like tokenization, part-of-speech tagging, and named entity recognition. → GitHub Repo
- NLTK - The Natural Language Toolkit, a comprehensive library providing tools for text processing, classification, tokenization, stemming, tagging, parsing, and semantic reasoning. → GitHub Repo
- transformers - A library by Hugging Face that provides architectures for natural language understanding and generation with pre-trained models, supporting tasks like text classification, information extraction, and text generation. → GitHub Repo
Orchestration
Orchestration tools manage and schedule complex workflows, ensuring that tasks are executed in the correct order and at the right time.
- Mage - An open-source tool for building data pipelines, enabling seamless integration and automation of data workflows. → GitHub Repo
- Airflow - A platform to author, schedule, and monitor workflows, offering a robust solution for managing complex data pipelines. → GitHub Repo
- Dagster - A tool for defining, executing, and monitoring data workflows, designed for machine learning, analytics, and ETL. → GitHub Repo
Stream Processing
Stream processing frameworks handle continuous data streams, enabling real-time data processing and analytics at scale. Unlike traditional batch processing, which processes data in large, static chunks, stream processing deals with data as it arrives, allowing for immediate insights and actions.
- Bytewax - Easy-to-use Python-native framework and platform for building distributed and scalable real-time data pipelines, leveraging Rust for efficient and speedy stream processing. → GitHub Repo
- PySpark - The Python API for Apache Spark, enabling large-scale data processing and stream processing using a distributed computing model. → GitHub Repo
- PyFlink - The Python API for Apache Flink, providing scalable and high-performance stream processing capabilities. → GitHub Repo
- Quix - A tool for building and managing data pipelines in Python, supporting various streaming use cases with a focus on ease of use. → GitHub Repo
- Faust - A stream processing library for Python, designed to handle real-time data streams and build distributed applications. → GitHub Repo
- Pathway - A business source license framework that offers stream processing capabilities, focusing on data transformation and analytics. → GitHub Repo
Machine Learning
Edge ML
Edge ML tools enable machine learning on edge devices, allowing for real-time data processing and analytics at the source.
- TensorFlow Lite - A lightweight version of TensorFlow designed for mobile and edge devices, enabling efficient on-device machine learning inference. → GitHub Repo
- edge-ml - A library providing machine learning algorithms optimized for edge computing, focusing on low-latency and resource-constrained environments. → GitHub Repo
Machine Learning
Machine learning libraries provide algorithms for data analysis and prediction, essential for building and deploying machine learning models.
- River - A library for online machine learning, enabling models to learn incrementally from a stream of data, suitable for real-time applications. → GitHub Repo
- Theano - A deep learning library that allows the definition, optimization, and evaluation of mathematical expressions involving multi-dimensional arrays. → GitHub Repo
- scikit-learn - A comprehensive library offering simple and efficient tools for data mining and data analysis, built on NumPy, SciPy, and matplotlib. → GitHub Repo
- XGBoost - An optimized distributed gradient boosting library designed to be highly efficient, flexible, and portable, often used for structured or tabular data. → GitHub Repo
- CatBoost - A gradient boosting library that handles categorical data automatically, providing powerful and efficient machine learning algorithms for classification and regression tasks. → GitHub Repo
Deep Learning
Deep learning frameworks enable the development of advanced neural networks for complex tasks such as image recognition and natural language processing.
- PyTorch - An open-source deep learning framework that provides a flexible and easy-to-use platform for building and training neural networks. → GitHub Repo
- Keras - A high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano, designed for fast experimentation. → GitHub Repo
- TensorFlow - An end-to-end open-source platform for machine learning, offering comprehensive tools and libraries to build and deploy machine learning models. → GitHub Repo
- fast.ai - A deep learning library that simplifies training fast and accurate neural networks, built on top of PyTorch and designed to enable practical deep learning. → GitHub Repo
Computer Vision
Computer vision libraries facilitate image and video analysis, enabling applications to interpret and process visual data.
- YOLO - An open-source object detection system known as "You Only Look Once," designed for real-time processing and high accuracy in detecting objects within images. → GitHub Repo
- scikit-image - A collection of algorithms for image processing, built on top of SciPy and designed to operate efficiently on NumPy arrays. → GitHub Repo
- OpenCV - An open-source computer vision and machine learning software library containing over 2,500 optimized algorithms for a wide range of image and video processing tasks. → GitHub Repo
GenAI
Vector Embedding Models
Vector embedding models offer pre-trained models for various NLP tasks, converting text into numerical vectors for analysis.
- Hugging Face - Provides a wide range of pre-trained models for NLP, including transformers that convert text into high-dimensional vectors suitable for various tasks. → GitHub Repo
- Voyage AI - Offers vector embeddings for advanced text analysis, enabling efficient and accurate representation of text data. → GitHub Repo
- Jina - Open-source framework for building neural search applications, leveraging vector embeddings to facilitate semantic search and retrieval. → GitHub Repo
- Mixed Bread - Provider of pre-trained models and vector embeddings designed to enhance NLP applications with rich, contextual text representations. → GitHub Repo
The go-to resource for Vector Embedding Models is the Hugging Face's MTEB Leaderboard, which showcases the performance of various models on the Massive Text Embedding Benchmark (MTEB).
Large Language Models
Large language models provide powerful text generation and understanding capabilities, performing tasks such as summarization and conversation generation.
- OpenAI - Develops state-of-the-art language models like GPT-4, offering advanced text generation, summarization, and conversational AI capabilities. → GitHub Repo
- Anthropic - Focuses on creating reliable, interpretable, and steerable AI systems, including large language models designed for safe and effective text processing. → GitHub Repo
- Mistral - Specializes in building high-performance language models aimed at providing robust text understanding and generation features. → GitHub Repo
- Gemini - Provides large language models that excel in various NLP tasks, including text generation, understanding, and conversation. → GitHub Repo
Choosing the right large language model depends on the specific requirements of your use case. This is a very dynamic space, so it is best to use the various performance leaderboards such as the LLM Leaderboard or the Hugging Face Open LLM Leaderboard for selecting an LLM.
Orchestration Frameworks
Orchestration frameworks help in building complex workflows involving multiple AI models and data sources, managing interactions between components.
- LangChain - Provides tools for creating and managing workflows that integrate various AI models and data sources, streamlining the development of complex AI applications. → GitHub Repo
- haystack - An open-source framework designed for building end-to-end NLP pipelines, enabling seamless orchestration of different models and data sources. → GitHub Repo
- LlamaIndex - Facilitates the integration and orchestration of multiple AI models, enhancing the efficiency and scalability of AI-driven solutions. → GitHub Repo
Experiment Tracking
Experiment tracking tools track, compare, and manage machine learning experiments, keeping track of model versions, parameters, and performance metrics.
- W&B - A platform for experiment tracking, model monitoring, and collaboration, making it easy to visualize and compare machine learning experiments. → GitHub Repo
- Comet - Provides tools for tracking, comparing, and optimizing machine learning experiments, offering insights into model performance and parameter tuning. → GitHub Repo
- MLflow - An open-source platform for managing the end-to-end machine learning lifecycle, including experiment tracking, model deployment, and reproducibility. → GitHub Repo
- DVC - Data Version Control system that integrates with Git to track data, code, and machine learning experiments, ensuring reproducibility and efficient collaboration. → GitHub Repo
Sinks
Vector Databases
Vector databases are optimized for storing and querying high-dimensional data, enabling efficient similarity searches and other vector operations.
- LanceDB - A vector database designed for large-scale data storage and retrieval, optimized for handling diverse data types and high-dimensional vectors. → GitHub Repo
- Milvus - An open-source vector database built for scalable similarity search, supporting high-throughput and low-latency queries on high-dimensional data. → GitHub Repo
- Qdrant - A vector similarity search engine that provides efficient and accurate querying of high-dimensional data, designed for seamless integration and scalability. → GitHub Repo
- Weaviate - An open-source vector search engine that combines vector search with traditional keyword search, supporting complex data models and real-time querying. → GitHub Repo
- Zilliz - A cloud-native vector database designed for AI applications, offering high performance and scalability for vector similarity search and analytics. → GitHub Repo
- Pinecone - A fully managed vector database service that provides fast and scalable similarity search, making it easy to integrate with machine learning models and applications. → GitHub Repo
- Chroma - A vector database focused on providing high-performance and scalable similarity search for machine learning applications. → GitHub Repo
- Elastic - A search and analytics engine that supports vector search capabilities, allowing for efficient similarity searches alongside traditional search operations. → GitHub Repo
A good comparison of the different vector databases on the market can be found on Superlinked's Vector Database Comparison.
Feature Stores
Feature stores manage and serve machine learning features, providing a centralized repository for feature data.
- Hopsworks - A feature store that offers a unified platform for feature engineering, storage, and serving, designed to support both real-time and batch feature data. → GitHub Repo
- Feast - An open-source feature store that provides a scalable and efficient way to manage, store, and serve machine learning features for training and inference. → GitHub Repo
- Vertex AI - Google Cloud's managed machine learning platform that includes a feature store, enabling easy sharing, discovery, and reuse of features across models and teams. → GitHub Repo
- Tecton - A fully managed feature store that streamlines the process of building, managing, and serving machine learning features, with support for real-time and batch processing. → GitHub Repo
- Amazon SageMaker Feature Store - Part of AWS SageMaker, this feature store provides a central repository to store, update, retrieve, and share machine learning features for both real-time and batch workflows. → GitHub Repo
Streaming Sinks
Streaming sinks enable real-time data storage and retrieval, allowing for immediate access to processed data.
- Redis - An in-memory data structure store used as a database, cache, and message broker, known for its high performance and support for real-time data processing. → GitHub Repo
- Google Dataflow - A fully managed streaming analytics service that allows for real-time data processing and analysis, supporting Apache Beam pipelines. → GitHub Repo
- Azure Stream Analytics - A real-time analytics and complex event-processing engine that provides real-time insights from data streams. → GitHub Repo
- Amazon Kinesis - A platform on AWS to collect, process, and analyze real-time, streaming data, providing powerful services for building real-time applications. → GitHub Repo
- ClickHouse - A fast open-source columnar database management system optimized for online analytical processing (OLAP), capable of handling real-time data streams and complex queries. → GitHub Repo
Relational Databases
Relational databases provide structured data storage and querying capabilities, supporting complex queries and data analysis.
- SQLite - A self-contained, serverless SQL database engine, widely used in mobile applications and small to medium-sized applications due to its simplicity and reliability. → GitHub Repo
- MariaDB - An open-source relational database management system, forked from MySQL, known for its performance, scalability, and rich feature set. → GitHub Repo
- PostgreSQL - An advanced open-source relational database known for its robustness, extensibility, and support for complex queries and transactions. → GitHub Repo
- MySQL - An open-source relational database management system, popular for web applications, known for its reliability, ease of use, and performance. → GitHub Repo
NoSQL Databases
NoSQL databases offer flexible data models, enabling efficient handling of unstructured and semi-structured data.
- MongoDB - A document-oriented NoSQL database known for its scalability and flexibility, allowing for the storage of JSON-like documents. → GitHub Repo
- Cassandra - A highly scalable, distributed NoSQL database designed to handle large amounts of data across many commodity servers without a single point of failure. → GitHub Repo
- DynamoDB - A fully managed NoSQL database service provided by AWS, offering fast and predictable performance with seamless scalability. → GitHub Repo
- Firestore - A flexible, scalable NoSQL cloud database for storing and syncing data for client- and server-side development, part of the Firebase platform by Google. → GitHub Repo
Application Layer
Data Visualization
Data visualization libraries enable the creation of interactive charts and dashboards, allowing for effective visualization of data insights.
- Bokeh - A Python library for creating interactive visualizations for modern web browsers, enabling detailed and complex data exploration. → GitHub Repo
- Plotly - Provides tools to create interactive graphs and dashboards, supporting a wide range of chart types and visualizations, with capabilities for both Python and JavaScript. → GitHub Repo
- Rerun.io - A platform for building data visualization dashboards, helping teams to quickly understand and interact with their data. → GitHub Repo
- Matplotlib - A comprehensive library for creating static, animated, and interactive visualizations in Python, widely used in data science. → GitHub Repo
- Seaborn - Built on top of Matplotlib, it provides a high-level interface for drawing attractive and informative statistical graphics. → GitHub Repo
- Redash - An open-source tool for visualizing and sharing the results of your queries, designed to enable quick insights from your data. → GitHub Repo
- Superset - An open-source data exploration and visualization platform designed to be enterprise-ready, supporting a wide variety of visualizations. → GitHub Repo
Logging & Monitoring
Logging and monitoring tools provide capabilities for tracking, monitoring, and alerting, ensuring the performance and reliability of applications.
- Grafana - An open-source platform for monitoring and observability, providing tools to visualize metrics, logs, and other data sources in customizable dashboards. → GitHub Repo
- Prometheus - An open-source monitoring system and time series database, designed for reliability and scalability, often used with Grafana. → GitHub Repo
- Elastic - Provides a powerful search engine with capabilities for log and time series analysis, operational visibility, and security analytics. → GitHub Repo
- Logstash - An open-source data collection engine with real-time pipelining capabilities, used to collect, transform, and ship data to a variety of destinations. → GitHub Repo
Data Applications
Frameworks for data applications enable the development of interactive data-driven applications, facilitating the deployment of real-time data solutions.
- Streamlit - A framework for creating interactive and visually appealing data applications in Python with minimal effort. → GitHub Repo
- FastAPI - A modern, fast web framework for building APIs with Python, based on standard Python type hints. → GitHub Repo
- Flask - A lightweight WSGI web application framework in Python, known for its simplicity and flexibility in building web applications. → GitHub Repo
- Count - A collaborative data notebook platform for building and sharing data applications and dashboards. → GitHub Repo
Model Serving
Model serving tools facilitate the deployment and serving of machine learning models, enabling real-time inference and predictions.
- Ray Serve - A scalable model serving library built on Ray, designed to deploy machine learning models in production. → GitHub Repo
- TensorFlow Serving - A flexible, high-performance serving system for machine learning models, designed for production environments. → GitHub Repo
- BentoML - An open-source platform that simplifies the deployment of machine learning models as REST APIs, providing tools for model packaging, serving, and monitoring. → GitHub Repo
Stay updated with our newsletter
Subscribe and never miss another blog post, announcement, or community event.
Streaming Data for Data Scientists: Part 2

Jonas Best
Chief of StaffJonas brings extensive experience from Accenture and Monitor Deloitte, where he managed projects at the intersection of technology and business. Before joining Bytewax, he attended business school at the University of St. Gallen and HEC Paris. He is crucial in coordinating Bytewax's strategic efforts and ensuring seamless operations.

