

At Bytewax, we believe stream processing should be accessible to everyone.
As organizations scale, handling stream processing efficiently becomes increasingly critical. Often, this involves working with Apache Kafka, a leading event-streaming platform. Managing Kafka streams can be complex, requiring multiple tools just to explore, process, and monitor your data. This fragmentation slows teams down. But what if you could do it all in one place? 🚀
With the upcoming Bytewax + Lenses integration, you can. This unified developer experience simplifies stream processing, making it easier to explore your data, process and transform it in real-time, and monitor it—all from a single interface.
Read on to learn why we love Lenses, what this integration means for our users, or jump straight into a real-world use case!
Why We Love Lenses
Lenses.io modernizes applications with data streaming. It has redefined the way engineers and data scientists interact with Kafka. With its sleek, intuitive interface and robust set of features, Lenses makes exploring streaming data an absolute breeze. Check out their community edition, it’s free! Here’s what we love about Lenses:
- Interactive Data Exploration: Lenses provides an immersive, real-time view of your Kafka streams: track event flows, validate message schemas, and query data in SQL. By giving you instant access to data insights via SQL Studio, Lenses reduces the friction between discovery and action.
- Powerful Monitoring & Alerts: The ability to monitor streaming pipelines and set up alerts means issues can be caught and resolved quickly.
- Governance & Developer Experience: Advanced governance and administration across any Kafka infrastructure.
- Deploy Anywhere: Just like Bytewax, Lenses is environment and infrastructure agnostic—from cloud to edge.
Who Should Care About Bytewax + Lenses Integration—And Why?
Streaming is powering next-generation applications & AI. Here are a few industries that could benefit from this integration:
- Retail – Real-time brand detection in retail environments provides a competitive advantage by tracking customer engagement in-store, processing visual data, and reacting in real time.
- Manufacturing & Automation – In industries like automotive manufacturing, real-time data streaming is critical for automation. Automakers rely on real-time analytics to optimize production lines and detect failures before they escalate.
- Finance – Financial institutions process vast amounts of unstructured data for AI-powered retrieval-augmented generation (RAG) systems, requiring both speed and precision.
- Logistics – Companies like Range depend on fleet management and AI-driven segment matching, relying on real-time IoT data, GPS tracking, and predictive analytics to optimize routes and reduce costs.
What Does It Mean For Our Users?

Our integration with Lenses.io means that Bytewax users can now:
- Discover what real-time data already exists with the Data Catalog
- Explore data with SQL without moving it in SQL Studio
- Move, prepare & transform data for AI processing
- Connect real-time data to a data store or application
- Monitor & alert on quality and pipeline health using Topology
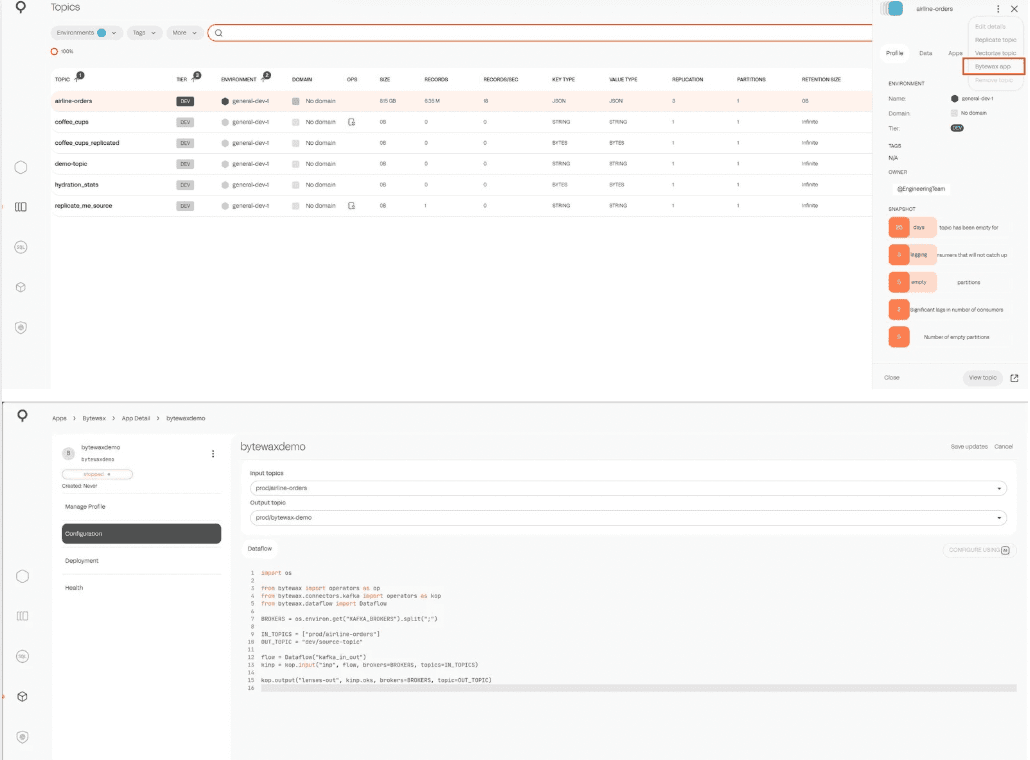
Here’s what excites us the most:
- Unified Experience: No more juggling between different tools or environments. With Lenses and Bytewax working together, you have one cohesive ecosystem for managing your streaming data.
- Accelerated Development: Rapid prototyping becomes even more efficient when you can instantly move from data discovery to processing. Identify trends, validate hypotheses, and deploy changes faster than ever.
- Enhanced Collaboration: Data teams can now share insights and iterate on processing pipelines. Lenses provides a clear picture of what's happening in your Kafka cluster, while Bytewax handles the heavy lifting of stream processing in a Python-friendly environment.
A Use Case: From Data Discovery to Actionable Insights
Let’s walk through a scenario where the integration truly shines—a day in the life of a data scientist or ML engineer using Bytewax and Lenses together.
Step 1: Discovering Data with Lenses
Picture this: You're monitoring a Kafka topic that collects user interaction events from your web application. With Lenses, you dive into the topic, inspect messages, and verify that your event schema is intact. The real-time dashboards give you a pulse on the data, highlighting any anomalies or interesting patterns.
Step 2: Building a Bytewax Dataflow
Armed with insights from Lenses, you decide it's time to process this raw data. You craft a Bytewax dataflow in Python to filter out noise, enrich the events with additional context, and aggregate metrics like session duration and click rates.
import os
from bytewax import operators as op
from bytewax.connectors.kafka import operators as kop
from bytewax.dataflow import Dataflow
BROKERS = os.environ.get("KAFKA_BROKERS", "localhost:19092").split(";")
IN_TOPICS = os.environ.get("KAFKA_IN_TOPICS", "in-topic").split(";")
OUT_TOPIC = os.environ.get("KAFKA_OUT_TOPIC", "out_topic")
flow = Dataflow("kafka_in_out")
kinp = kop.input("inp", flow, brokers=BROKERS, topics=IN_TOPICS)
op.inspect("inspect-errors", kinp.errs)
msgs = kop.deserialize("de", kinp.oks)
def extract_identifier(msg):
return msg.key["identifier"]
keyed = op.key_on("key_on_identifier", msgs.oks, extract_identifier)
def accumulate(acc, msg):
acc.append(msg.value["value"])
return acc
windows = op.window("calc_avg", keyed, accumulate)
def calc_avg(key_batch):
key, batch = key_batch
return {
"identifier": key,
"avg": sum(batch) / len(batch),
}
avgs = op.map("avg", windows.down, calc_avg)
kop.output("out1", avgs, brokers=BROKERS, topic=OUT_TOPIC)Step 3: Observing & Iterating
After deploying your Bytewax dataflow, you switch back to Lenses to monitor the output Kafka topic. Seeing the enriched and aggregated data rolling in gives you confidence that the pipeline is working as intended. And if something needs tweaking? It’s all part of the rapid feedback loop—observe, iterate, and improve.
Looking Forward
At Bytewax, we’re passionate about empowering our users to harness the full potential of streaming data. Our integration with Lenses.io is not just about connecting two powerful tools—it’s about creating an ecosystem where data flows seamlessly from exploration to action.
We’re excited to see how our community will innovate with this new integration, building smarter, faster, and more resilient streaming applications. Here's to a future where every byte of data drives meaningful impact!
Stay tuned, and happy streaming! 🚀
Stay updated with our newsletter
Subscribe and never miss another blog post, announcement, or community event.
Announcing the Bytewax Connector for S2!

Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.
Integrating Bytewax with SingleStore for a Kafka Sink
Other posts you may find interesting
View all articles

Integrating Bytewax with SingleStore for a Kafka Sink
A step-by-step guide to using Bytewax to move Kafka data into SingleStore efficiently.
Written by Zander Matheson & David Selassie