

Stream processing can be defined as taking action on a continuous stream of data at the time the data is being created. This allows users to perform real-time analysis on data in-flight and before storage. For example, stream processing is used for credit card fraud detection, where fraudulent transactions are analyzed and blocked as the card is swiped.
Operations provided by stream processing engines can be stateful or stateless. With stateful stream processing, the state of the past event is persistent, influencing how the next event in the stream processes. Whereas in stateless stream processing, the state is not persistent.
Stateful stream processing is used for real-time recommendations, pattern detection, or complex event processing. Stateful stream processing allows holding application data in a local state to be used by different components of the application. In this article, we will be discussing examples for both stateful and stateless stream processing products.
Why Do You Need Stream Processing?
Stream processing has a number of benefits to offer your organization:
Respond to data changes in real time: Stream processing lets you respond to new data events as they occur. Therefore, stream processing happens in real time. This lets developers detect conditions in data at the moment they occur, giving you results faster than other data processing technologies.
Reduce data storage costs: Stream processing is very useful if the data volume is significant and can incur a large storage cost. With stream processing, you can reduce this storage cost because the source data is processed in real time, avoiding any need to store it first.
Decouple components for easier application management: It's easier to maintain and update applications when stream processing is used as the components they interface with (data sender and receiver) are decoupled.
Protect against data loss: Since stream processing applications can temporarily hold data up to a certain limit, they also serve as ad hoc backup solutions for critical systems such as stock market or banking applications. In case the data receiver is offline, the stream processor can still hold the data destined for it and thereby reduce data-loss risk.
Stream from multiple data sources: Stream processing is also useful in applications such as multiplayer video games where streaming data arrives from multiple sources. This data can be processed in real time and reduce the load on the application server.
Comparison of Popular Stream Processing Frameworks
This article will explore and compare popular stream processing products, namely Apache Flink, Apache Storm, Apache Samza, Apache Beam, Apache Kafka, and Bytewax. These frameworks are all open source and free to use.
They also support many types of applications, such as e-commerce sites, critical applications such as banking systems, stock market apps, etc. E-commerce sites, in particular, find stream processing useful to persist shopping carts even after the session expires.
Since all of these frameworks are open source applications, there's extensive community support, and some are powered by tech giants such as Yahoo!, Twitter, Spotify, etc.
The Apache products chosen in this article naturally complement each other. For example, Kafka and Storm can be easily integrated.
Apache Flink
 Image courtesy of Apache Flink
Image courtesy of Apache Flink
Apache Flink is an open source stream processing framework that has excellent performance, with low latency and high throughput. We added this to our list because it states a good example for stateful, distributed stream processing and is fault tolerant. Flink has the ability to handle large scales of data. It uses local file systems such as HDFS, S3, or RocksDB for storage.
Apache Flink supports programming languages such as Java, Scala, and Python. It works on the Kappa architecture that has a single processor for the stream of input.
Flink supports many features:
- Batch and streams
- Persistent state
- Operations such as joins and aggregations (including over aggregation, group aggregation, and window aggregation)
Apache Flink is licensed under the Apache License 2.0 and is best suited for event-driven applications and data pipelines.
Apache Storm
 Image courtesy of Usama Ashraf/Hackernoon
Image courtesy of Usama Ashraf/Hackernoon
Apache Storm is an open source product mainly known for its performance and high speed. We added this to our list because it has many use cases apart from real-time analytics, such as online machine learning and distributed RPC. Like Flink, it's also scalable and fault tolerant.
Apache Storm supports any programming language, including Java. It uses the HDFS distributed file system as storage. Storm uses a primary/worker architecture. The primary node is called Nimbus, and the worker nodes are called supervisors. For coordination, the architecture uses ZooKeeper.
A few important points to note about Storm are as follows:
- It's a stream-only framework. However, it supports micro–batch processing to a certain extent.
- It doesn't support persistent state.
- It supports operations such as joins and aggregations.
Storm is licensed under the Apache License 2.0 and is best suited for applications that require very low latency, such as dynamic pricing for retail stores and fraud detection on credit card swiping machines.
Apache Samza
 Image courtesy of Apache Samza
Image courtesy of Apache Samza
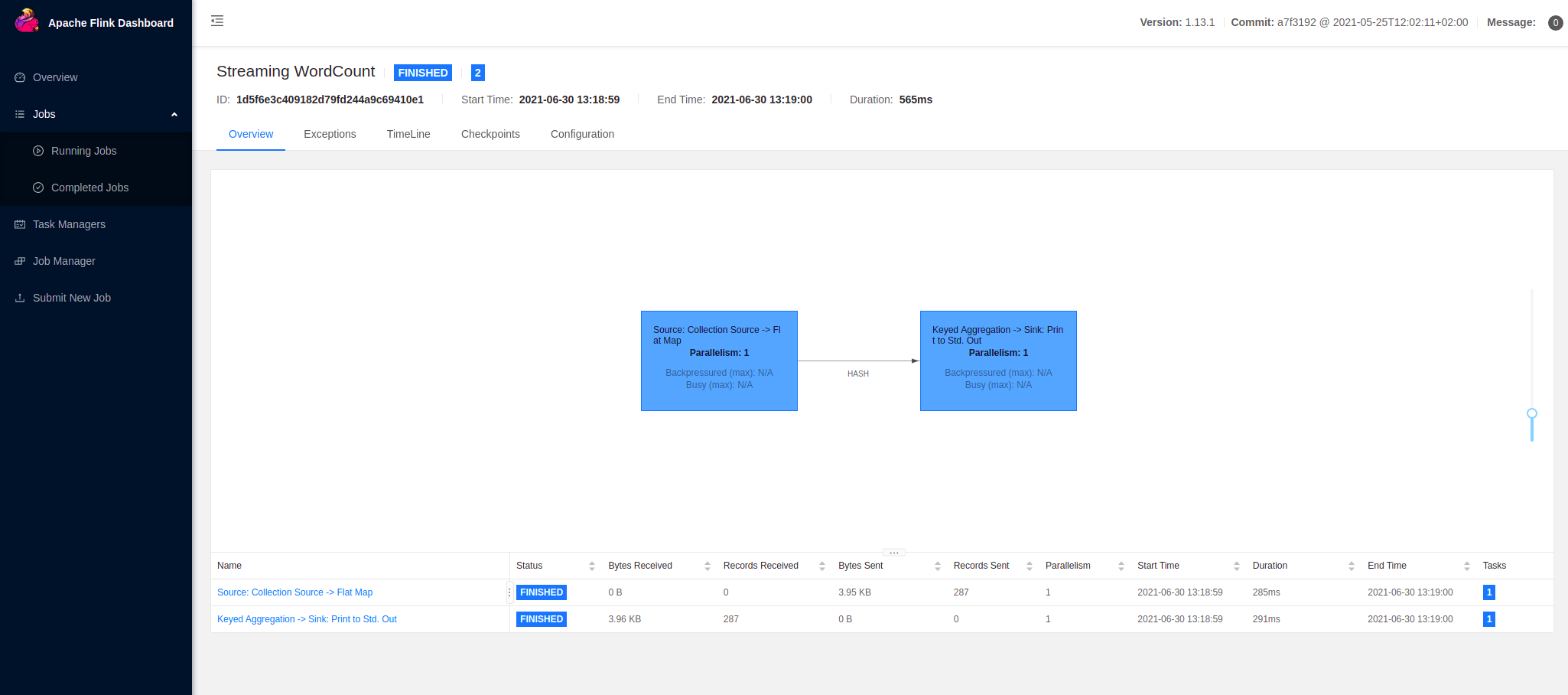
Apache Samza is known for horizontal scalability and high performance and allows you to process data in real time from multiple sources. We included this framework in our list because of the many benefits it offers, such as flexible deployment options with YARN, Kubernetes or standalone, as well as powerful low-level and high-level APIs.
Samza stores data in a local state on the same machine as the stream task. Its architecture has three layers, namely the streaming layer (Kafka), the execution layer (YARN), and the processing layer (Samza API). This follows a similar pattern to Hadoop. Samza supports JVM languages only.
Samza supports the following features:
- Joins and aggregations (primitives are provided to do joins and aggregations)
- Persistent state
Samza is a stream-only framework and doesn't support batches. It's licensed under the Apache License 2.0 and is best suited for applications that include fraud combating, performance monitoring, and notifications; applications where multiple teams are processing the same data stream at various stages; and applications that have exactly-once delivery guarantee requirements.
Apache Beam
Apache Beam is open source, unified, extensible, portable, and centralized. We added it to our list because it allows highly parallel data processing tasks—problems can be decomposed into smaller pieces and processed in parallel.
Beam supports multiple languages such as Python, Java, Go, and SQL. The Beam architecture/model comprises I/O connectors, SDK, the processing type, and the Beam runner. The Beam pipeline runner translates the data processing pipeline to a backend that can execute the pipeline. It defines connectors for cloud databases such as Google Cloud Storage.
Beam has many features, including support for:
- Both batch and streams
- Persistent state
- Aggregation operations
Beam doesn't support joins. It's licensed under the Apache License 2.0 and suited for applications with highly parallel data processing tasks, such as financial risk management, climate data modeling, and video color correction.
Apache Kafka
Apache Kafka, which includes Kafka Streams, is an open source event streaming platform for mission-critical applications; on their home page, they state that more than 80 percent of all Fortune 500 companies use Kafka.
We added this platform to our list because of the many benefits it provides, such as being a durable message store, handling a very high throughput with limited resources, and having an ability to scale.
Kafka supports Java and Scala, including the higher-level Kafka Streams library, for languages such as Go, Python, C/C++, and many other programming languages. It uses the solid-state drives (SSDs) of the servers that Kafka runs on, cloud databases, or an internal RocksDB for storage. The architecture of Kafka is a partitioned log model that combines the concepts of messaging queues and publish-subscribe.
Kafka (including kafka-streams) supports many features:
- Joins and aggregations
- Persistent state
- Both batch and stream processing for large amounts of data
Kafka is licensed under the Apache License 2.0 and is best suited for applications that require activity tracking, log aggregation, stream processing, and event sourcing.
Bytewax
Bytewax is an open source Python framework for building highly scalable data flows. It has many advantages, such as having no vendor lock-in and no JVM,simple scaling, and being cloud native. Bytewax has operations such as capture, filter, map, and reduce.
Bytewax allows you to recover a stateful dataflow to enable fault tolerance. It uses a durable state storage system such as SQLite or Kafka for this purpose. Its architecture includes a Python native binding to the Timely Dataflow library. Timely Dataflow is used to handle worker communication and execution. Bytewax supports the following features:
- Joins and aggregations
- Persistent state
- Both batch and stream processing
It's best suited for applications written in Python that require parallelprocessing. The operators in Bytewax allow it to operate on individual parts of data concurrently. Bytewax is licensed under the Apache License 2.0.
Conclusion
Insights and automation derived from processing data can greatly increase the success of a business, and in certain cases, even more so when decisions need to be made as soon as the data is available. Streaming frameworks such as Apache's Flink, Storm, Kafka, Samza, Beam and Bytewax all allow you to conduct real-time data analysis through stream processing.
Stay updated with our newsletter
Subscribe and never miss another blog post, announcement, or community event.
Comparison of Stream Processing Frameworks Part 2

Viduni Wickramarachchi
ContributorViduni works as a software engineer and has been a technical writer for over five years. She holds an MSc in Advance Software Engineering from the University of Westminster and a BSc (Hons) in Computer Science from the University of Colombo.


{kind=link}
{kind=link}
{kind=link}