

Streaming Feature Extraction for a ML Pipeline using Memphis.dev and Bytewax
By Anastasia Khomyakova

This blog post is inspired by the presentation "Streaming Feature Extraction for a ML Pipeline using Memphis.dev and Bytewax" given by a member of our community RJ Nowling at the SBTB conference in Oakland last year.
In the world of machine learning, the ability to make accurate, real-time predictions stands as a pillar of technological advancement.
These predictions power a multitude of applications, from ride-sharing apps estimating your wait time to dynamic pricing models in e-commerce.
At the core of these sophisticated ML models lies a critical process: the transformation of raw data into a structured format that algorithms can interpret and learn from.
Can you do feature extraction and predictions in real-time?
💯 Absolutely!
The following diagram demonstrates a typical machine learning pipeline, showing how raw data is processed and enriched at various stages to produce a real-time prediction:
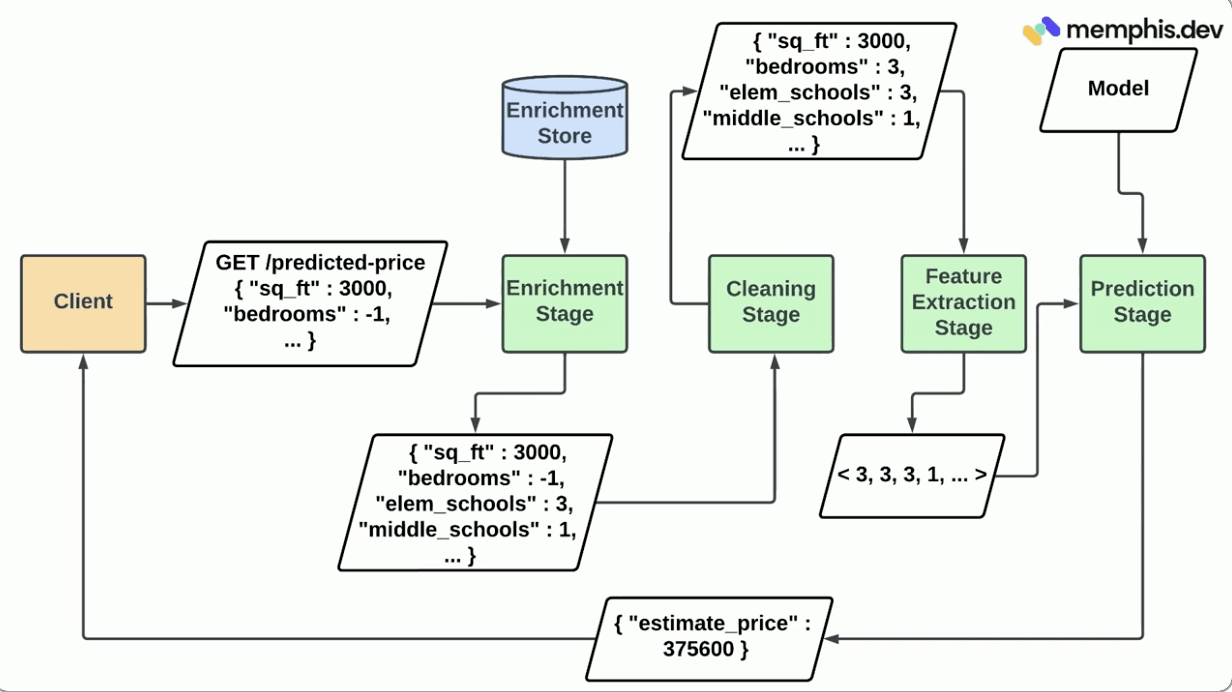
In this process:
- A Client sends data to our system (e.g., a request for a predicted property price).
- The data goes through an Enrichment Stage where it's augmented with additional information from the Enrichment Store (e.g., schools in the area).
- Next, it enters a Cleaning Stage to resolve any inconsistencies or missing values.
- At the Feature Extraction Stage, the enriched and cleaned data is converted into a numerical vector.
- This vector is then used in the Prediction Stage to estimate the price using an ML model, with the result sent back to the client.
Feature extraction involves transforming raw data into a set of numerical values or "features" that represent the data in a way that can be processed by ML models. This process is crucial because ML models, at their core, approximate mathematical functions that operate on numerical vectors, not on unstructured records.
What do I need to implement this online predictions pipeline?
🔄 Ability to do Real time Transformations of Raw Data 🔑💾 Key Value Storage to Pull Enrichement Data from 🕒 Stateful Transformations for Dynamic Insights 🌍 Ability to communicate between separate services in real-time (message broker or pub/sub)
! Real world example ! The challenge of capturing time-sensitive patterns in road traffic: the necessity of converting timestamps into periodic signals to help ML models grasp the concept of time periodicity.
Solution: Real-Time Prediction with Memphis.dev and Bytewax.
As listed above, the dynamic nature of real-time predictions requires efficient and scalable solutions for data processing and feature extraction.
Memphis.dev serves as a durable and scalable platform for managing high-volume, real-time data streams, ensuring that data is consistently routed and processed with minimal latency.
Usage Scenario: In a real-time recommendation system, Memphis.dev could manage and route user interaction data to ensure that the recommendation engine is always using the most current information, enabling truly dynamic user experiences.
Bytewax offers a Python-native framework for building data processing pipelines that can perform complex transformations, including real-time feature extraction and stateful data updates.
Usage Scenario: For ad targeting based on clickstream analysis, Bytewax can process incoming streams to update user profiles in real-time, ensuring that ad placements are always relevant and timely.
Constructing Robust ML Pipelines
By leveraging Memphis.dev for stream management and Bytewax for data processing, developers can create ML pipelines that are not just responsive, but predictive, adapting to incoming data with minimal delay.
A practical example is in predictive maintenance for industrial equipment.
- Memphis.dev orchestrates the sensor data streams, ensuring their prompt delivery to processing nodes.
- Bytewax can then analyze this data in real-time, identifying patterns that may indicate equipment failure, thereby enabling preemptive maintenance actions.
This capability is crucial across various applications, ensuring that predictions are both fast and accurate, directly impacting user experience and decision-making processes in the real world.
For the full details on how to build the pipeline, watch RJ's talk here.
Bonus! Enrichement of Data: Providing Context for Better Predictions.
Richer Data Context: Integrating external datasets (like socioeconomic indicators from the American Community Survey for real estate apps, or weather data for transportation and logistics) adds valuable context to the primary dataset. This enriched context helps ML models make more informed predictions by understanding the broader factors influencing the target variable.
Dynamic Enrichment for Real-Time Relevance: By augmenting real-time data streams with complementary data, models can adapt to changes in external conditions (such as weather or market trends) almost instantaneously. This adaptability is crucial for applications where conditions affecting predictions can change rapidly.
P.S. Our thanks go to RJ Nowling for his informative presentation, a highlight for our community. RJ, holding a Ph.D. from the University of Notre Dame and serving as an Associate Professor of Computer Science at MSOE, combines his academic pursuits with practical industry experience.

His work focuses on the application of machine learning to genomic data, underpinned by his foundational research in mathematical models and statistical analyses. His commitment to applying ML in real-world scenarios, both in the classroom and through collaborative research, enriches our collective knowledge and practice in the field.
Check out the full talk recording here.
Stay updated with our newsletter
Subscribe and never miss another blog post, announcement, or community event.

