
Real-time data pipelines with Python: introducing the Bytewax cheatsheet
By Laura Funderburk & Jonas Best

This cheatsheet provides an overview of the key concepts and operators in Bytewax, helping you to quickly grasp its features and integrate them into your workflows effectively.
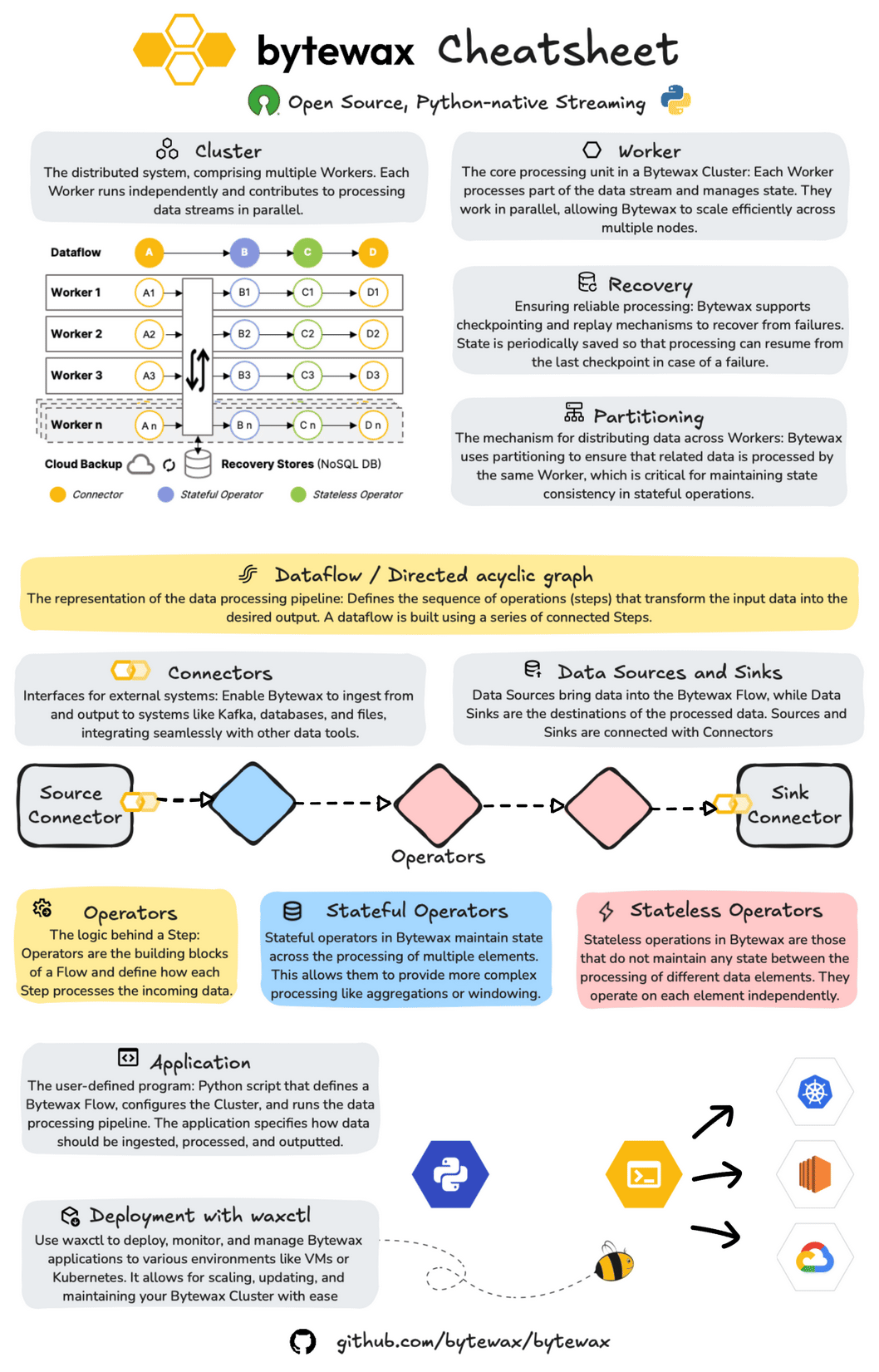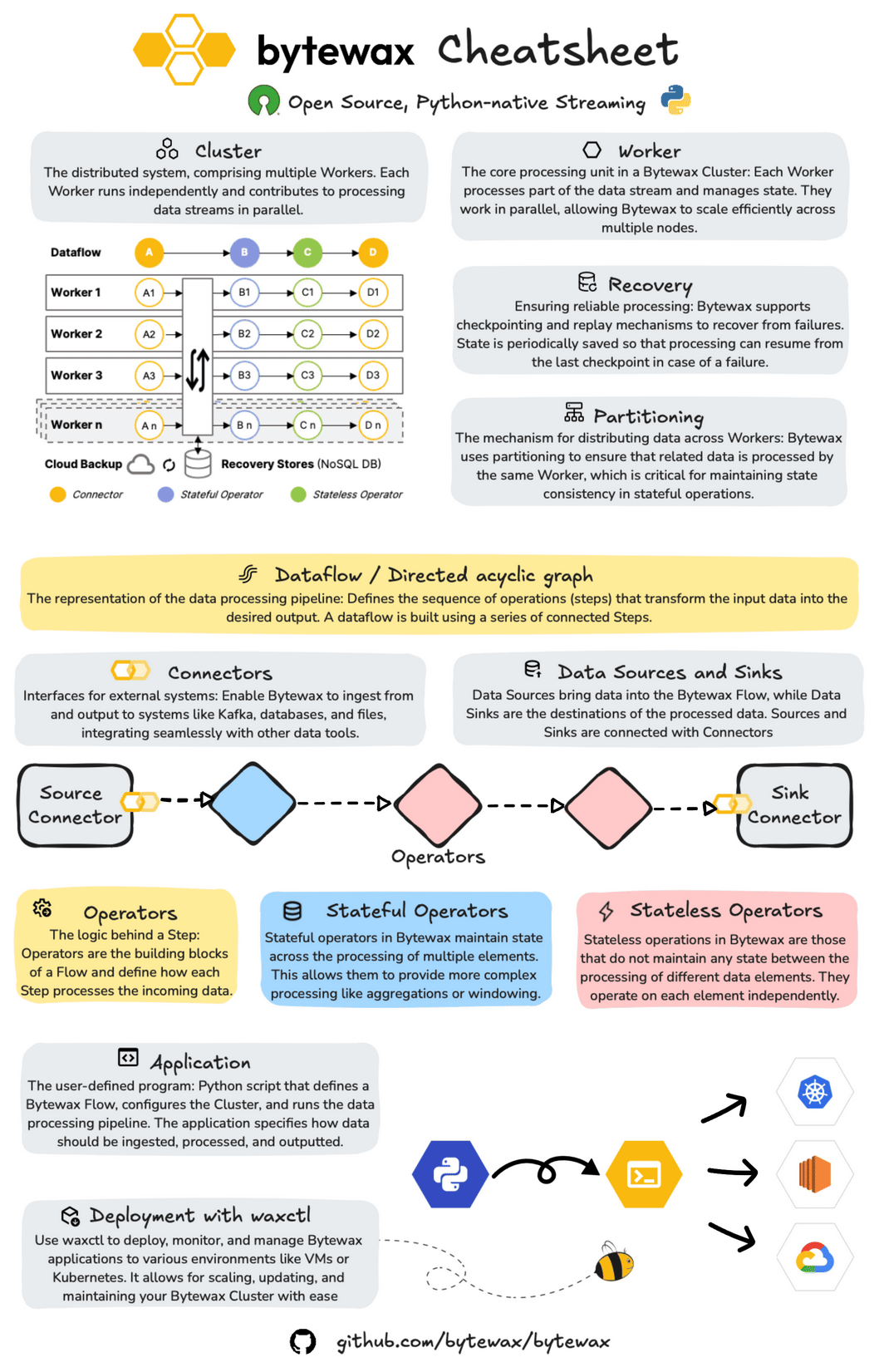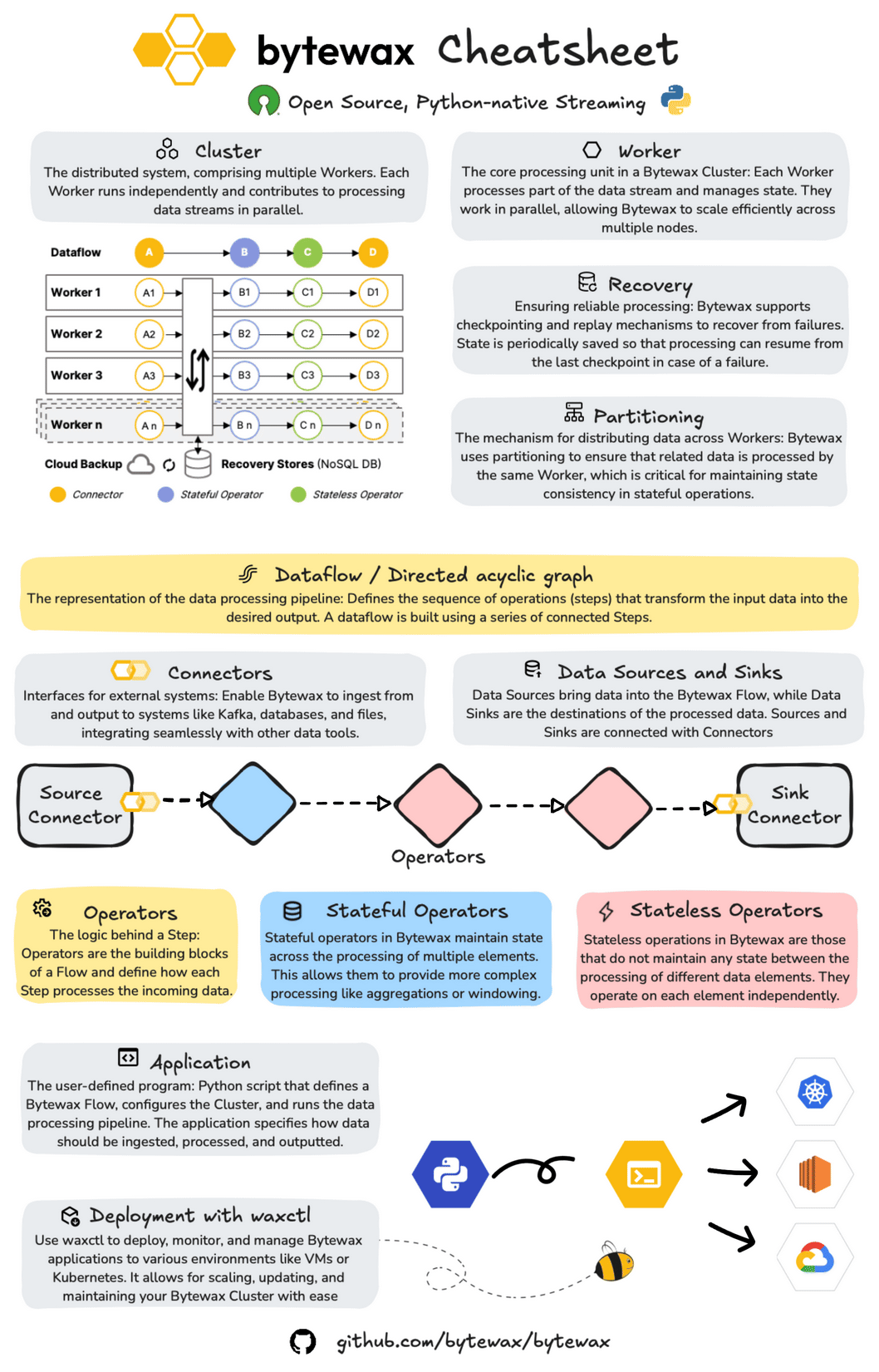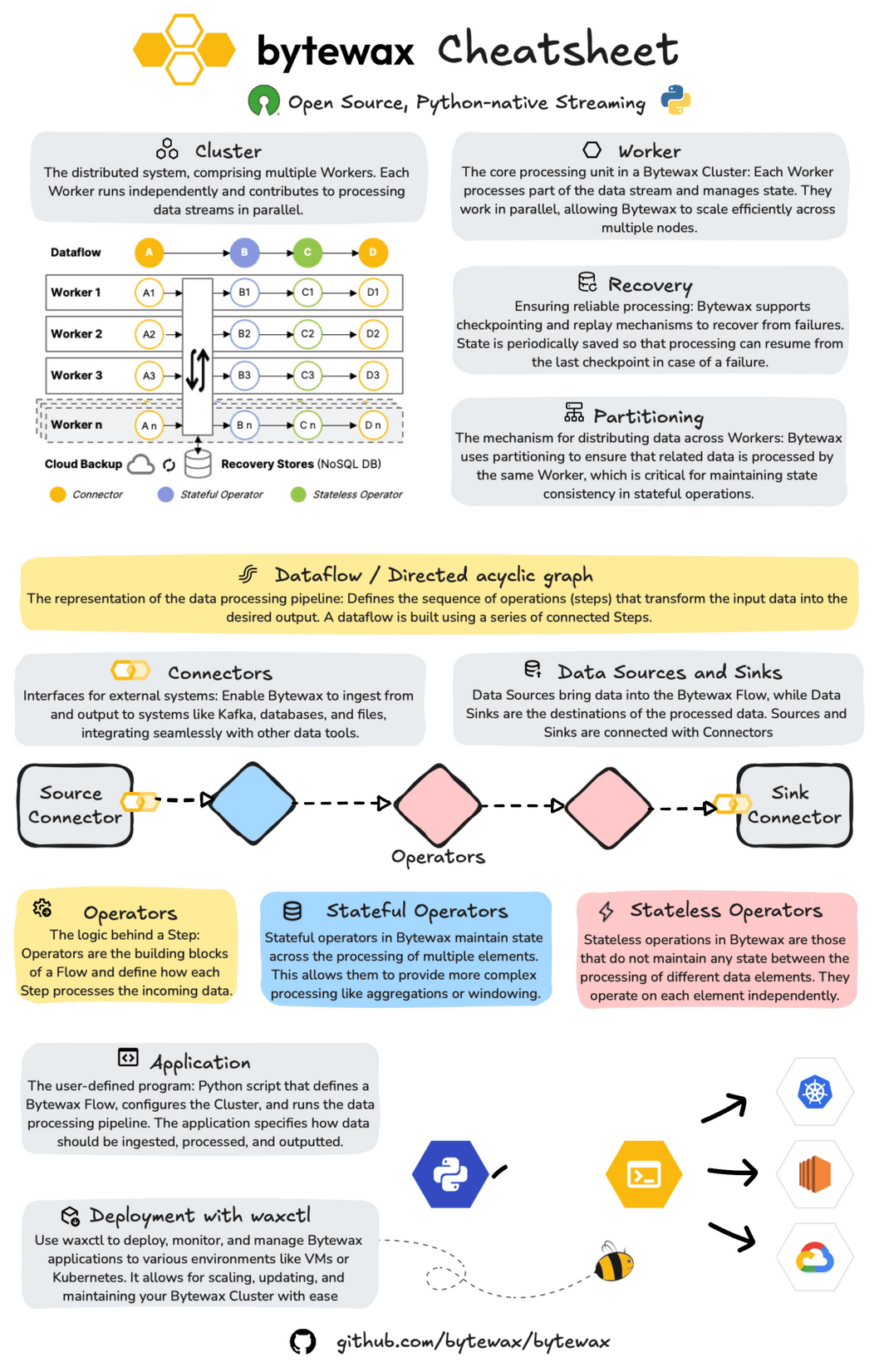
About Bytewax
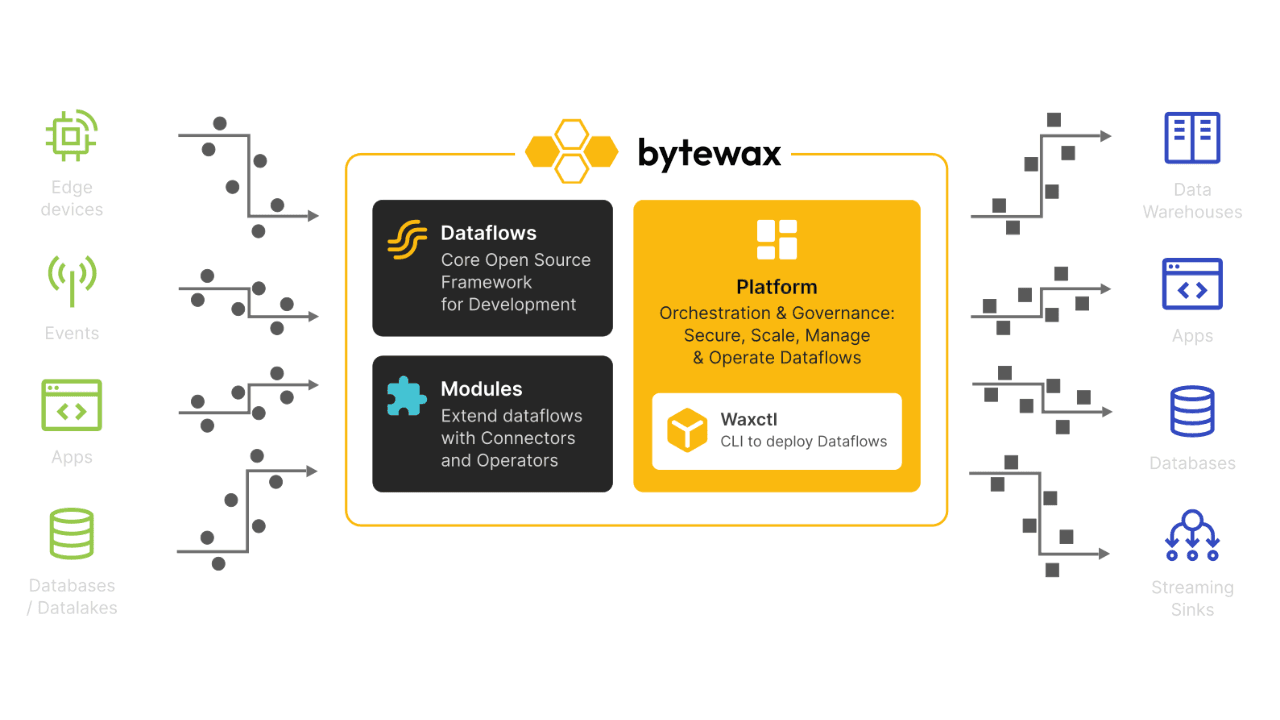
Bytewax is an open-source, Python-native streaming framework designed for building and managing distributed data processing applications.
At its core, Bytewax operates within a cluster architecture, where multiple Workers independently process different segments of the data stream. This setup facilitates efficient parallel processing across multiple nodes, enhancing scalability and performance. Bytewax also includes robust recovery mechanisms, allowing dataflows to resume from the last checkpoint in case of failure, ensuring consistent and reliable processing.
Additionally, Bytewax’s partitioning capabilities ensure that related data elements are processed by the same Worker, which is crucial for maintaining state consistency in stateful operations.
It is built on Rust's timely dataflow and provides a Python API, enabling developers to build real-time dataflows while leveraging the Python ecosystem.
To get started, you can install Bytewax via the command:
pip install bytewaxLet's get started with a simple dataflow.
Structuring Your Pipeline with Bytewax Dataflow, Operators and Connectors
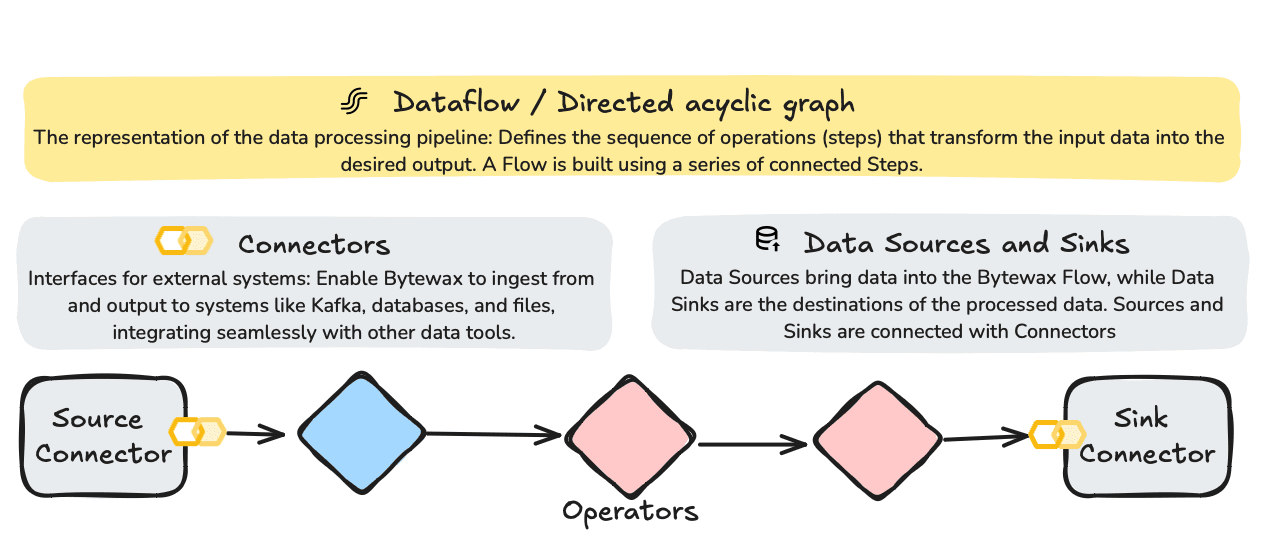
Dataflows in Bytewax are structured as Directed Acyclic Graphs (DAGs), with each node representing a processing step. This structure is key to defining the sequence of operations that transform input data into the desired output.
Bytewax connectors enable seamless integration with external systems, allowing for efficient data ingestion and output. This example uses a standard input/output connector, but you can replace it with specific connectors like Kafka or files.
Operators in Bytewax define the logic applied to data as it flows through the pipeline. Operators can be stateful or stateless.
When combined, these elements enable the creation of real-time end-to-end processes that allow you to transform raw data, and store it and serve it in real time.
Sample dataflow
The dataflow below will set up a simple Bytewax dataflow that processes a list of strings by converting each string to uppercase.
from bytewax.dataflow import Dataflow
import bytewax.operators as op
from bytewax.testing import TestingSource
from bytewax.connectors.stdio import StdOutSink
from bytewax.testing import run_main
# Create and configure the Dataflow
flow = Dataflow("upper_case")
# Input source for dataflow
inp = op.input("inp",flow, TestingSource(["apple", "banana", "cherry"]))
# Define your data processing logic
def process_data(item):
return item.upper()
# Apply processing logic
out = op.map("process", inp, process_data)
# Output the results to stdout through an StdOutSink,
# the StdOutSink can easily be changed to an output
# such as a database through the use of connectors
op.output("out", out, StdOutSink()) This dataflow can be executed as follows, assuming it is stored in a file named dataflow.py:
python -m bytewax.run dataflow:flowYou can visualize its mermaid graph as follows:
python -m bytewax.visualize dataflow:flowTestingSource, and Bytewax source input connectors in general, use "lazy" loading behind the scenes through the use of generators, optimizing performance.
The dataflow can also be rewritten using lambda functions:
# Create and configure the Dataflow
flow = Dataflow("stateless_example")
# Input source for dataflow
inp = op.input("inp", flow, TestingSource(["apple", "banana", "cherry"]))
# Apply stateless mapping
out = op.map("uppercase", inp, lambda x: x.upper())
op.output("out", out, StdOutSink()) Deployment
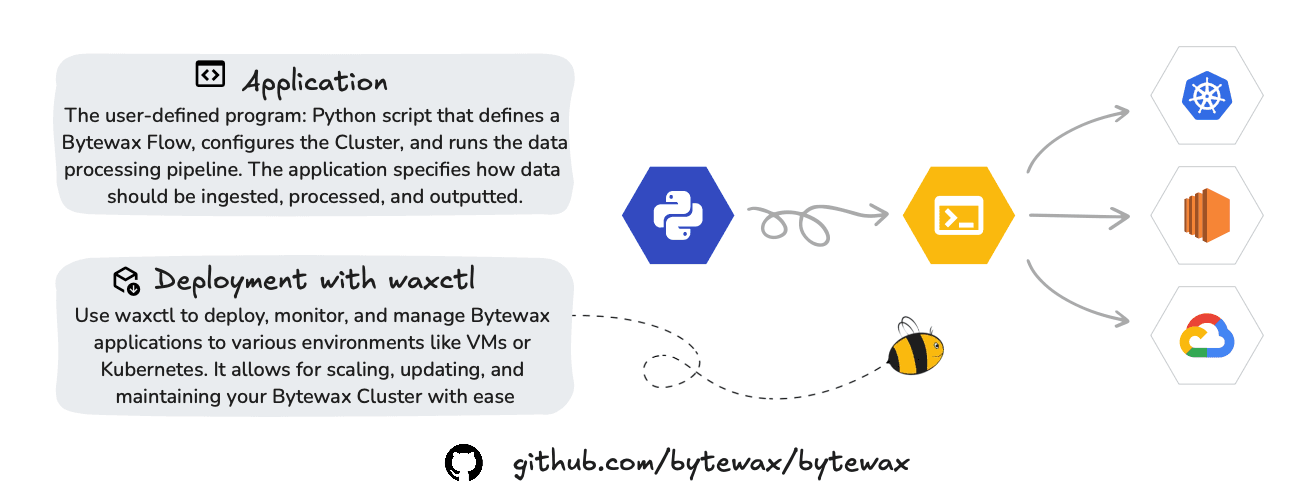
Bytewax allows for easy deployment and management of streaming applications across various environments, from local setups to cloud-based deployments.
https://docs.bytewax.io/stable/guide/deployment/waxctl.html
Bytewax enables you to deploy and manage your dataflows through a CLI.
Waxctl allows you to manage the entire dataflow program lifecycle which includes these phases:
- Deployment
- Getting Status
- Modification
- Deletion
waxctl dataflow --help
Manage dataflows in Kubernetes.
Usage:
waxctl dataflow [command]
Aliases:
dataflow, df
Available Commands:
delete delete a dataflow
deploy deploy a dataflow to Kubernetes creating or upgrading it resources
list list dataflows deployed
Flags:
-h, --help help for dataflow
Global Flags:
--debug enable verbose output
Use "waxctl dataflow [command] --help" for more information about a command.Bytewax also provides a platform to manage dataflows, and the platform may be deployed locally, on cloud and even on a Raspberry Pi.
Conclusion
Bytewax is a framework designed for building real-time data processing pipelines using Python. By integrating with the Python ecosystem and leveraging Rust's Timely Dataflow, Bytewax provides both flexibility and performance for a wide range of data processing tasks.
The framework offers a clear and intuitive API, a diverse set of operators, and deployment tools like waxctl to facilitate the development, deployment, and management of real-time dataflows. Bytewax is suitable for handling both straightforward data streams and more complex distributed workflows, making it a versatile option for various use cases.
In our next blog, we will provide an in-depth overview of Bytewax operators and windowing.
Stay updated with our newsletter
Subscribe and never miss another blog post, announcement, or community event.
Understanding Bytewax Operators for Distributed Data Processing
Laura Funderburk
Senior Developer AdvocateLaura Funderburk holds a B.Sc. in Mathematics from Simon Fraser University and has extensive work experience as a data scientist. She is passionate about leveraging open source for MLOps and DataOps and is dedicated to outreach and education.

Jonas Best
Chief of StaffJonas brings extensive experience from Accenture and Monitor Deloitte, where he managed projects at the intersection of technology and business. Before joining Bytewax, he attended business school at the University of St. Gallen and HEC Paris. He is crucial in coordinating Bytewax's strategic efforts and ensuring seamless operations.

