
Building Real-Time RAG for Financial Data and News
We're teaming up with Microsoft and Unstructured to bring you an incredible workshop, hosted by AICamp.
In this workshop, we will focus on designing RAG pipelines through data flow pipeline design including Directed Graphs (DG), and the integration of real-time analytics.
Discover the knowledge and skills needed to set up and manage real-time Retrieval Augmented Generation (RAG) pipelines using both structured and unstructured financial data.
One of the challenges of financial data is how quickly it becomes irrelevant - both in terms of the market prices and any events around it.
The event is 🆓 free and expected to last ⏰ 2 hours.
- Leverage Bytewax for integrating real-time analytics into your data processing workflows.
- Incorporate Unstructured to process image and web based information
- Incorporate Azure AI services to deploy and manage RAG pipelines
Below is a diagram showing how all the components work together.
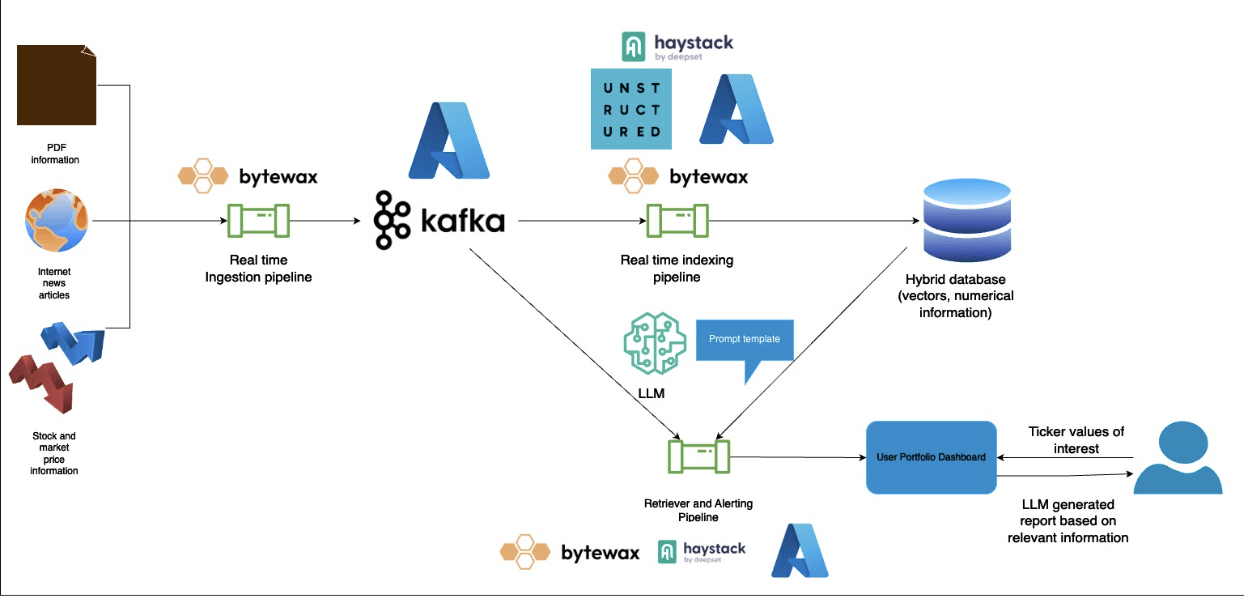
❗️ More details you can find in out blog.
Guiding you through this experience will be

Zander Matheson
CEO, Founder at Bytewax
Laura Funderburk
Senior developer advocate at Bytewax
Shagun Sharma
Data Scientist at Microsoft via TCS
Nina Lopatina
Staff Developer Relations Engineer at Unstructured🙋♂️🙋♀️ Audience
🛠️ Data/ML/AI engineers;
🔬 Data scientists;
💻 Software engineers interested in data processing;
📊 IT professionals looking to understand and apply RAG.
Workshop prerequisites
- Basic Understanding of Data Structures and Algorithms
Familiarity with fundamental concepts in data structures and algorithms is required. This includes knowledge of arrays, linked lists, stacks, queues, trees, and basic algorithmic principles.
- Proficiency in Python Programming
Comfortable with writing and debugging Python code. Experience with Python libraries commonly used in data processing and machine learning, such as Pandas, NumPy, and Scikit-learn.
- Knowledge of Data Processing and ETL Concepts
Understanding of data extraction, transformation, and loading (ETL) processes. Experience with handling structured (e.g., CSV, JSON) and unstructured (e.g., text, images) data.
[Optional] To reproduce the solution - not required to participate in the webinar
- Setup of Required Azure Services
- Get Unstructured API Key and Install Unstructured Tools
- Obtain an API key from Unstructured by signing up on their platform.
- Follow API documentation to set up your connectors and ingest your documents to your destination.
- Clone this repository and install dependencies
- git clone
- cd real-time-rag-workshop/
- Pip install -r requirements.txt
Nina Lopatina
Staff Developer Relations Engineer at UnstructuredShagun Sharma
Data Scientist at Microsoft via TCSLaura Funderburk
Senior developer advocate at BytewaxZander Matheson
CEO, Founder at Bytewax