

On February 16th at 9:00 AM PST, Bytewax and Soflandia will conduct a collaborative online workshop, hosted by AIcamp. This free workshop, focusing on the intersection of AI and real-time communication, is scheduled to last approximately 2 hours. Participants will learn how to build a RAG-enhanced Slackbot.
Your takeaway from this workshop will be a RAG supercharged slackbot.
Resources
- Workshop can be completed on Windows, macOS or Linux. The host will be using Python 3.11 on Linux;
- Slack workspace which we will use for the workshop. Please ensure you're in prior to the event. API key for the LLM endpoint will be shared in the workshop Slack at the beginning of the workshop, and it will be disabled at the end of the workshop.
- Documents to be ingested in Qdrant will be shared in the git repository and Slack. Adding your own documents to your own Qdrant instance is also allowed, as long as they are appropriate.
The agenda
1. Introduction (5 minutes)
We'll start with a brief introduction of the technologies we will use.
- Bytewax is a Python-native open-source framework and distributed stream processing engine. Made to build streaming data pipelines and real-time apps with everything needed. Able to run in the cloud, on-prem and on edge devices.
- Qdrant is a vector database & vector similarity search engine. It deploys as an API service providing search for the nearest high-dimensional vectors. Qdrant's expanding features allow for all sorts of neural network or semantic-based matching, faceted search, and other applications.
- LLM (Large Language Model) is an advanced AI model for generating human-like text. Trained on extensive datasets, it excels in various NLP tasks, offering contextually relevant responses. Ideal for automated customer service, content creation, and more, LLMs enhance communication across platforms. In this workshop, we'll be using YOKOT.AI, Softlandia's flagship Generative AI Solution. It lets the user chat with their documents, crawl the internet for more documents, and generate new content based on existing documents and user input. Watch YOKOT.AI demo on YouTube.
- RAG (Retrieval Augmented Generation) is an AI architecture that boosts Large Language Model (LLM) capabilities by integrating retrieval-based information with generative responses. This approach allows for more accurate and detailed answers to complex queries, enhancing the overall LLM experience by providing contextually enriched content. For further reading on RAG and YOKOT.AI please refer to this article.
We will also go through the agenda and pre-shared materials.
2. Setup (20 minutes)
Install and configure Bytewax into a Python environment
Bytewax currently supports the following versions of Python: 3.8, 3.9, 3.10 and 3.11.
We recommend creating a virtual environment for your project when installing Bytewax. For more information on setting up a virtual environment, see the Python documentation.
Once you have your environment set up, you can install Bytewax. We recommend that you pin the version of Bytewax that you are using in your project by specifying the version of Bytewax that you wish to install:
pip install bytewax==0.18.1Read more about installing Bytewax in our documentation.
Install and configure the Qdrant vector database
Get the Python client with
pip install 'qdrant-client[fastembed]'The client uses an in-memory database. You can even run it in Colab or Jupyter Notebook, no extra dependencies required. See an example.
3. A basic data stream (20 minutes)
This step is to build a basic data stream. The central concept of Bytewax is a dataflow, which provides the necessary building blocks for choreographing the flow of data. Within Bytewax, a dataflow is a Python object that outlines how data will flow from input sources, the transformations it will undergo, and how it will eventually be passed to the output sinks.
Here, we will be using Slack as an input source, and StdOutSink as a sink.
Bytewax connects to a variety of input sources and output sinks, check out our Getting Started example, Polling Input Example, and more in the blog.
4. LLM + RAG (40 minutes)
The central part of the workshop covers LLM and RAG. We'll track what the conversation is about using LLM. We'll branch our stream to separate messages that contain a query. To generate responses to the queries, we will use LLM and RAG techniques.
Let's take a look at the diagram:
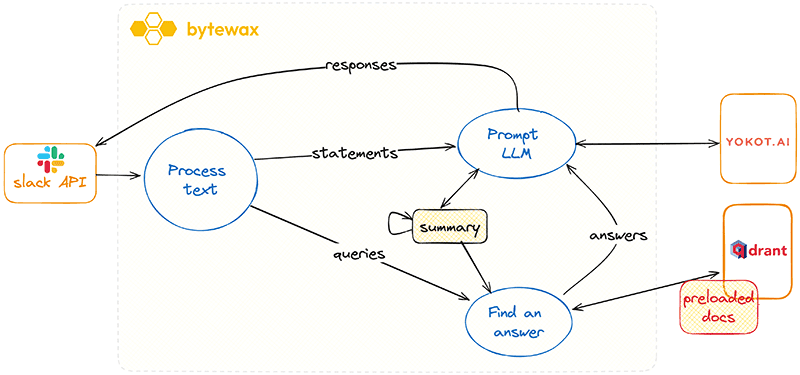
Slack API: This is where the workflow initiates, with the system receiving textual input through Slack's API.
Process Text: In this phase, we analyze the input text to determine whether it is a statement or a question/query. If it is identified as a statement, it is sent to Yokot.AI for a summary. If the text is a question, it will be passed down a different workflow path to find an answer
Prompt LLM: During this step, the system engages with an LLM (Yokot.AI) to generate summaries and formulate responses, depending on the type of input identified in the previous step.
Summary: Summaries generated by the LLM are stored in Bytewax's state and can be accessed as needed. Note that if scaling is required, Bytewax manages this state across various workers, ensuring data is routed correctly for stateful operations.
Find an Answer: To find canonical answers to questions, the system leverages data from preloaded documents and the Qdrant component. These answers also take into account the summaries that have been generated and stored in the state. Embeddings will be created using Qdrant with fastembed.
The final step: is to send the responses back. For simplicity, we will start with the
StdOutSinkand switch to the Slack API if time allows.
5. Bonus! Feedback loop (20 minutes, if time allows)
Once we build our pipeline, we can ask questions and receive RAG-enriched responses. But so far, we've been using the StdOutSink. In this step, we replace it and will see how to push responses back to a Slack channel.
6. Recap (15 minutes)
We'll wrap up with a demo! And discuss what we learned and where to go next.
Speakers:
Henrik Nyman, Co-Founder & Senior Software Architect at Softlandia Oy. Henrik is a distinguished software architect and co-founder of Softlandia Ltd. His expertise spans the design of complex systems such as fully automated factory lines and state-of-the-art measurement devices. The practical experience is paired with a proficiency in Python, C/C++, Rust, and hardware integration, together with a field knowledge in optics, robotics and metrology.
Mikko Lehtimäki, Co-Founder & Data Scientist at Softlandia Oy. Mikko is a data scientist, researcher and software engineer and one of the founders of Softlandia Ltd. He has a long background in working with data in all ways possible. Mikko has contributed to Llama-index and Guardrails-AI, two of the leading open-source initiatives in the LLM space. He is also the beloved host of our Data Science Infrastructure meetups.
Zander Matheson, Founder & CEO at Bytewax. Zander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.
Couldn't join our workshop?
No problem!
We have the entire session recorded for you 👇
Stay updated with our newsletter
Subscribe and never miss another blog post, announcement, or community event.
Celebrating 1000 stars on GitHub ⭐️

Oli Makhasoeva
Director of Developer Relations and OperationsOli is a passionate technologist with a background in engineering, consulting, and community building. On a break from creating content, she loves to network online & in person at meetups, conferences, and forums.